Привет, я Антон, backend-разработчик в CosySoft. В этом цикле статей (1, 2) я рассказываю про Apache NiFi — инструмент для работы с потоками данных, который мы используем в проекте.
Это третья часть моего цикла статей про Nifi. Здесь делюсь практическими рекомендациями: где NiFi действительно помогает, где его стоит использовать с осторожностью, а где — лучше обойти стороной.
Покажу примеры интеграции между сервисами, расскажу, почему не стоит переносить бизнес-логику в NiFi, и разберу типичные проблемы, с которыми сталкивался сам.
Рекомендации по использованию Nifi
Далее будет мое мнение о том, в каких случаях можно использовать Nifi, а в каких случаях лучше несколько раз подумать об альтернативах. В основном рассмотрим различные кейсы в контексте архитектурного проектирования систем (System Design).
Можно использовать
Рассмотрим ситуации, в которых использование Nifi оправдано и принесет пользу.
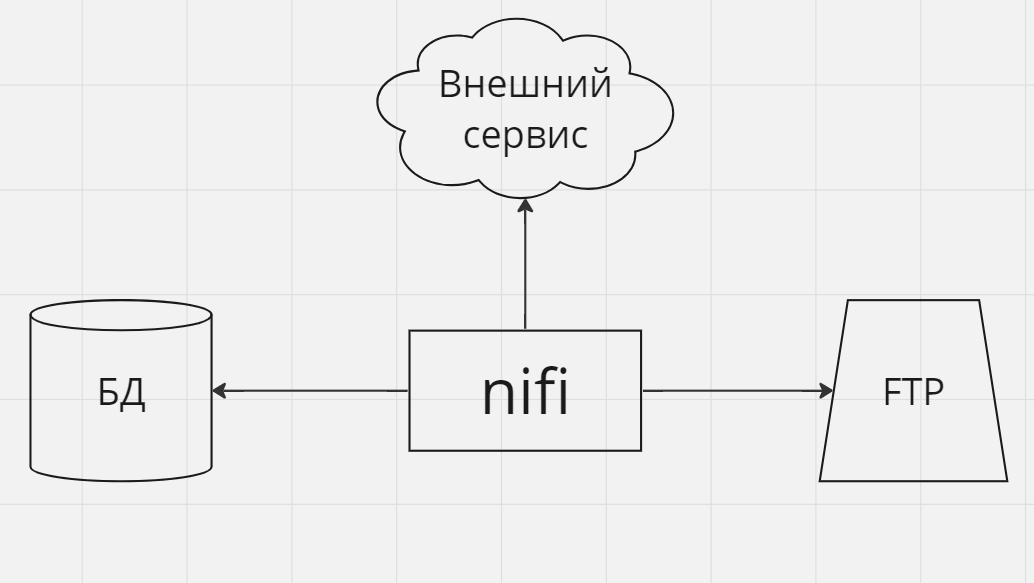
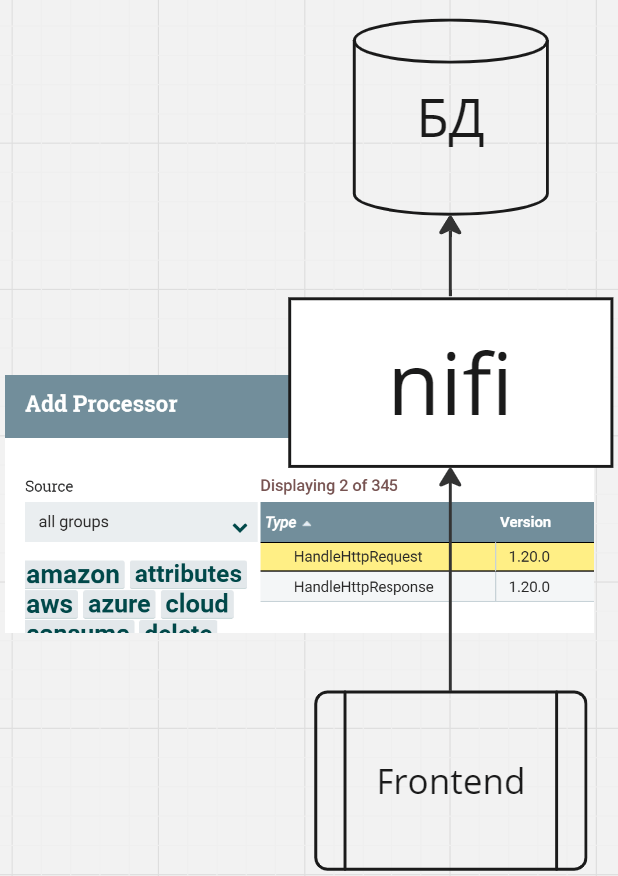
Как средство интеграции между различными сервисами в кластере
Nifi можно использовать в качестве системы-посредника между сервисами, как локальными (разворачиваемых в рамках вашей инфраструктуры), так внешними (предоставляемыми внешними вендорами). Особенно это удобно в случаях, когда интеграция не сводится к простому случаю 1 к 1.
В таких ситуациях Nifi не обязан занимать центральное место в архитектурном ландшафте, он применяется как точечное средство для заполнения пустоты между сервисами в тех местах, где его применение оправдано сложностью и/или разнообразием интеграций.
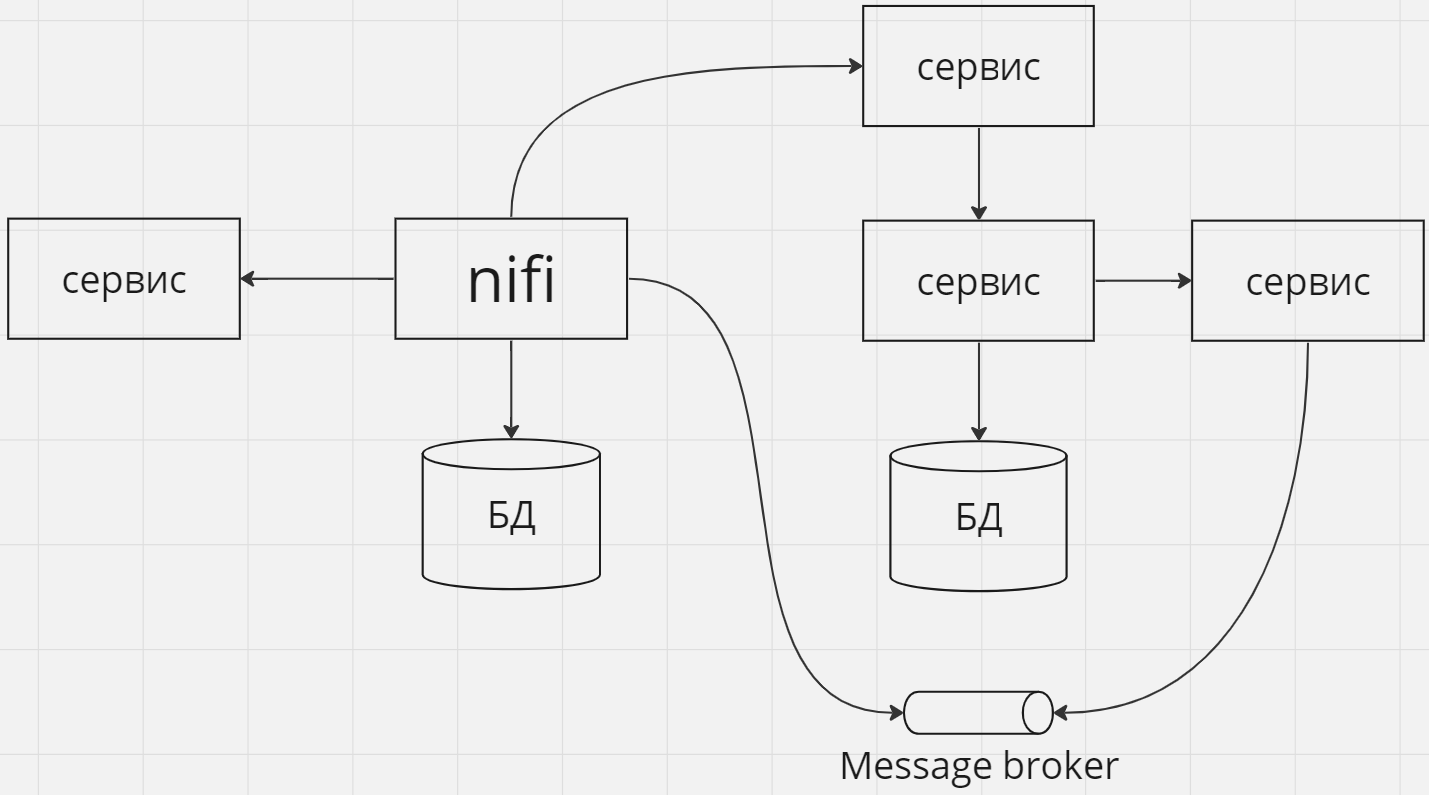
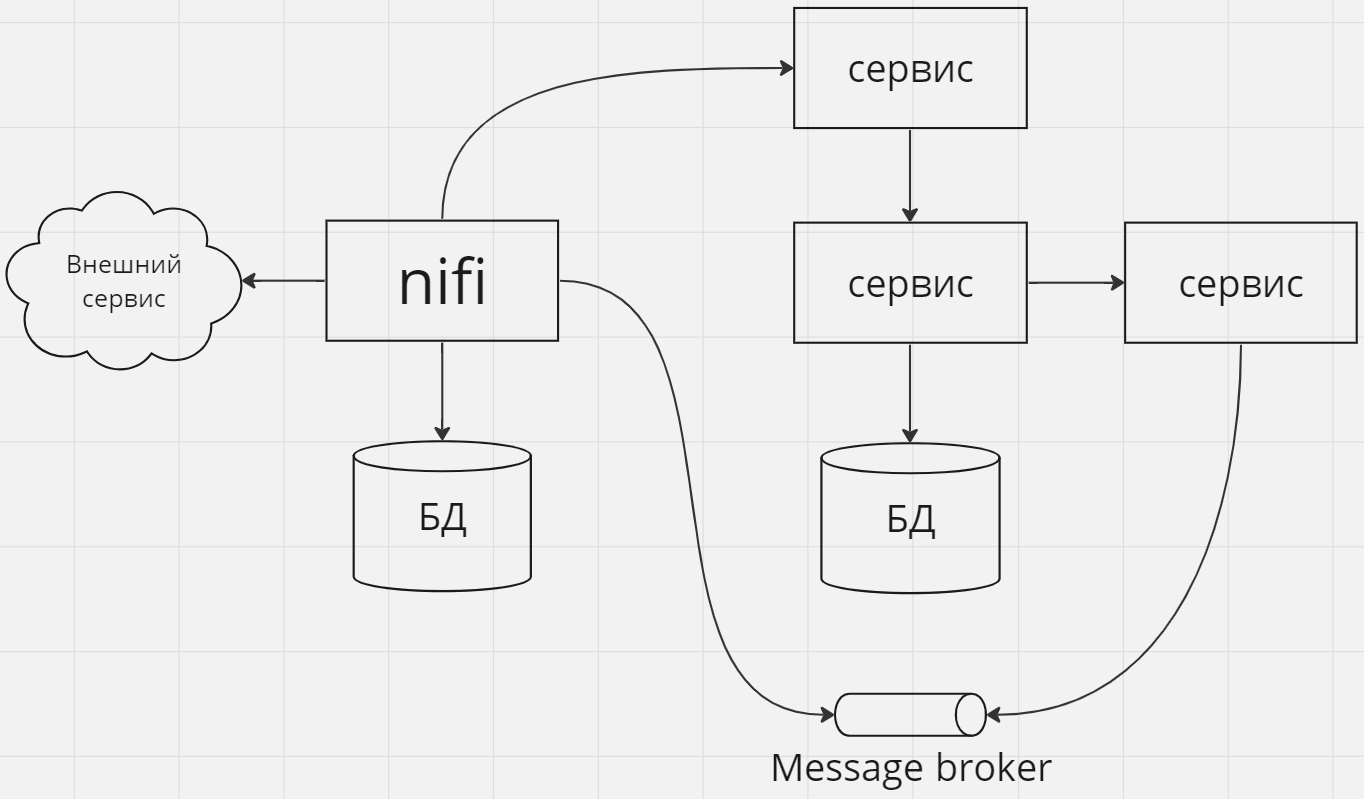
На приведенных схемах здесь и далее стрелки показывают направление зависимостей если не сказано иного.
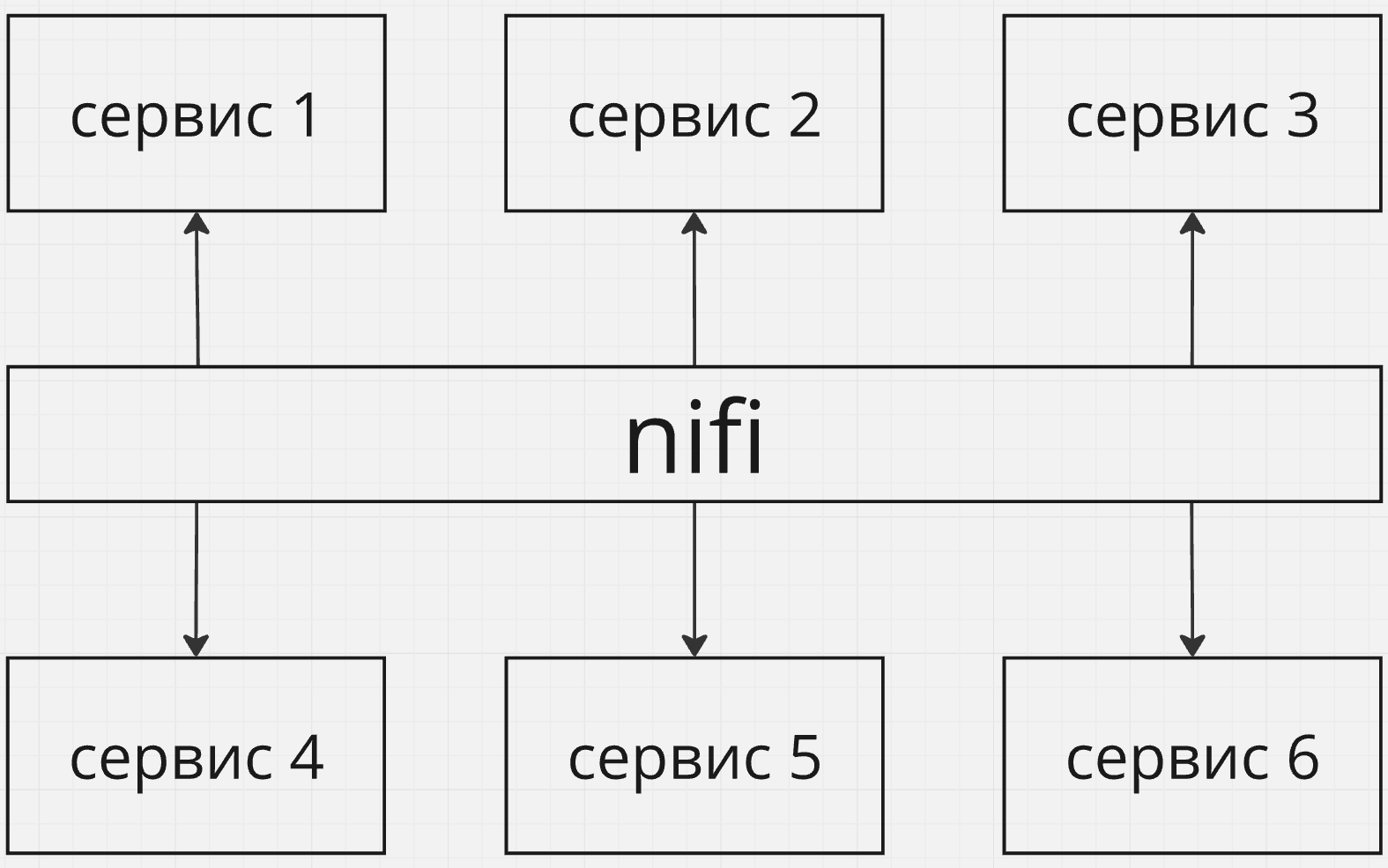
Интеграция с большим количеством источников и/или потребителей
Nifi можно использовать в тех случаях, когда ваш поток данных нужно собрать с большого количества разнородных источников, или наоборот отправить в большое количество разнородных потребителей. В таких случаях Nifi можно рассматривать как архитектурный фасад, скрывающий сложный конгломерат систем-источников или систем-потребителей данных.
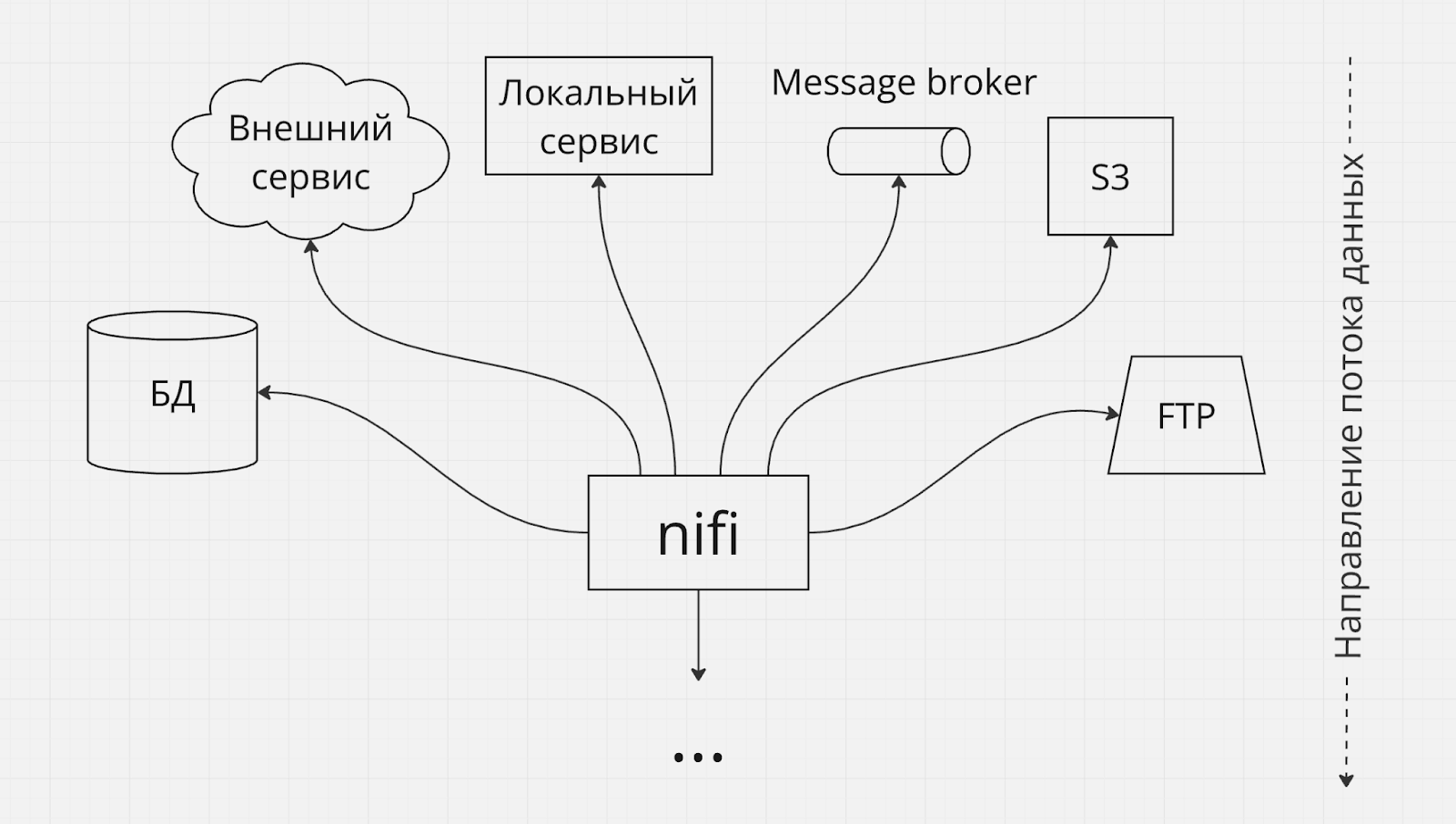
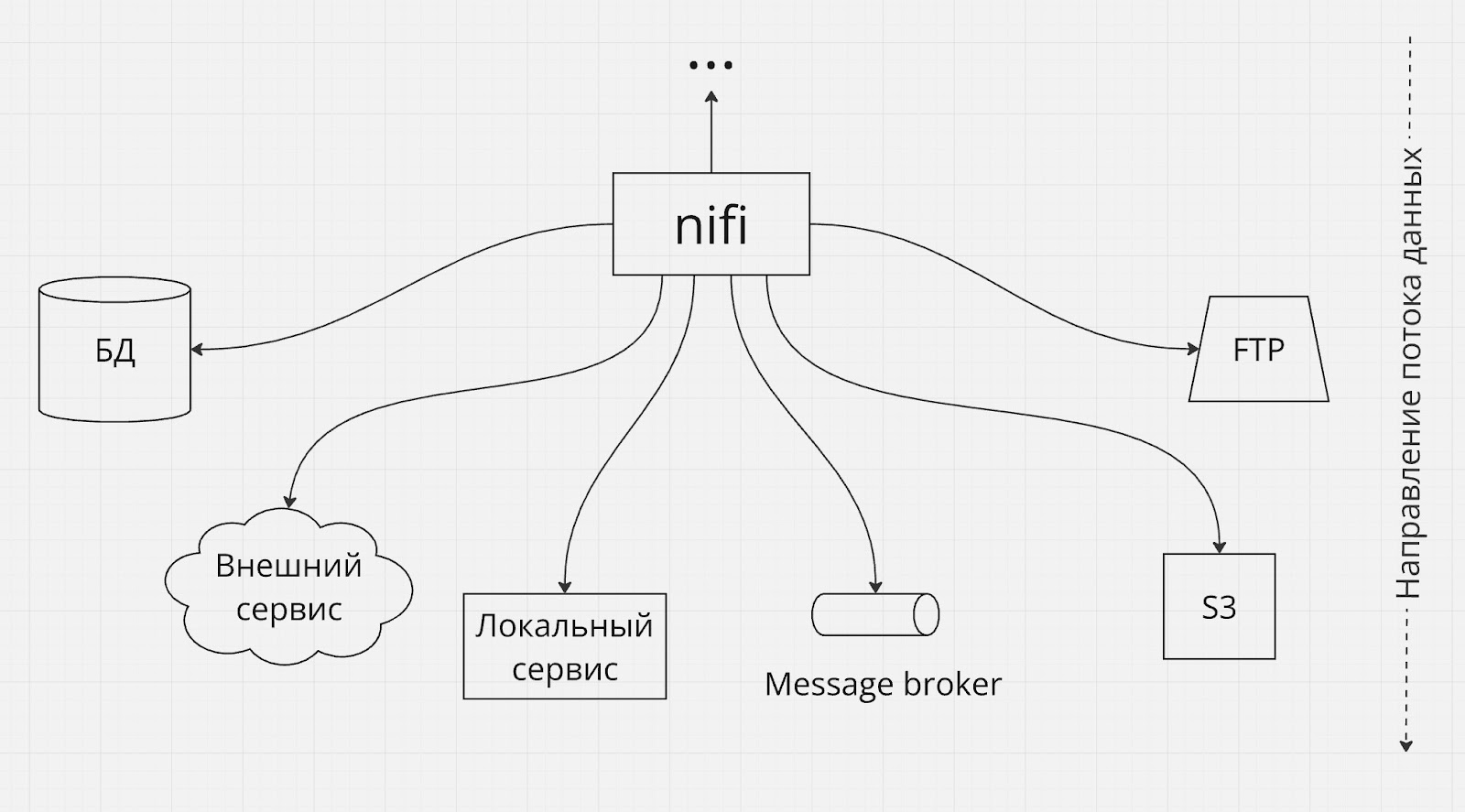
No-code solutions
Если у вас небольшая бизнес логика, автоматизация информационных процессов не является ключевым аспектом вашего бизнеса, и вам требуется компактное решение, для которого нецелесообразно создавать полноценную IT-инфраструктуру с командой разработки, нанимая соответствующие объемы персонала, Nifi может стать приемлемым и доступным решением. Вам конечно придется нанять грамотного системного аналитика (который будет настраивать потоки данных в Nifi) и системного администратора для конфигурирования Nifi и обслуживания сервера, но это не идет ни в какое сравнение с полноценными командами разработки и сопровождения.
Также, Nifi отлично подходит для личных нужд, если вам надо что-то автоматизировать самостоятельно “в домашних условиях”.
Автоматизация информационных процессов через пайплайны обработки stream-данных
В некоторых случаях Nifi может становиться центральным ядром вашей архитектуры, вокруг которого выстраивается автоматизация ваших информационных процессов или по крайней мере важным звеном в глобальном стеке обработки данных. Nifi в силу заложенных в него паттернов отлично подходит на роль платформы, на которой вы строите обработку данных по принципу pipeline-архитектуры. Такая архитектура на мой взгляд особенно хорошо подходит для обработки потока данных, по-минимуму требующих участия человека в контексте ручного ввода дополнительных данных на промежуточных этапах обработки (не путать с настройкой, контролем и управлением процессом, здесь ваше участие может потребоваться). Обычно это различные задачи сбора и обработки больших объемов данных для последующей аналитики.

Включение / выключение потока данных
Иногда может появиться потребность временно приостановить конкретный поток данных, например из-за того, что сервис потребил большое количество данных из брокера сообщений и требуется дать ему время на обработку возникшего затора, не увеличивая его новыми порциями данных. Конечно такие потребности можно решать и другим способом, например вертикальным или горизонтальным масштабированием с параллельной обработкой, но мы живем в неидеальном мире, где всплески количества данных могут происходить внезапно, или где нет бюджета на масштабирование. Останавливать источник данных (если он вообще под вашим контролем) нецелесообразно, т.к. другие потребители могут быть не заинтересованы в паузах.
Другой пример – вы хотите провести деплой новой версии сервиса, а ваш программный фреймворк, на котором он реализован, не поддерживает graceful shutdown. Опять же, скорее всего в вашем проекте есть контрмеры против несогласованных состояний после внезапных отключений, т.к. никто не отменяет вероятность аварий, но такие контрмеры могут быть не самыми простыми и дешевыми операциями. Удобно иметь под рукой ручной переключатель для контролируемого запланированного обслуживания.
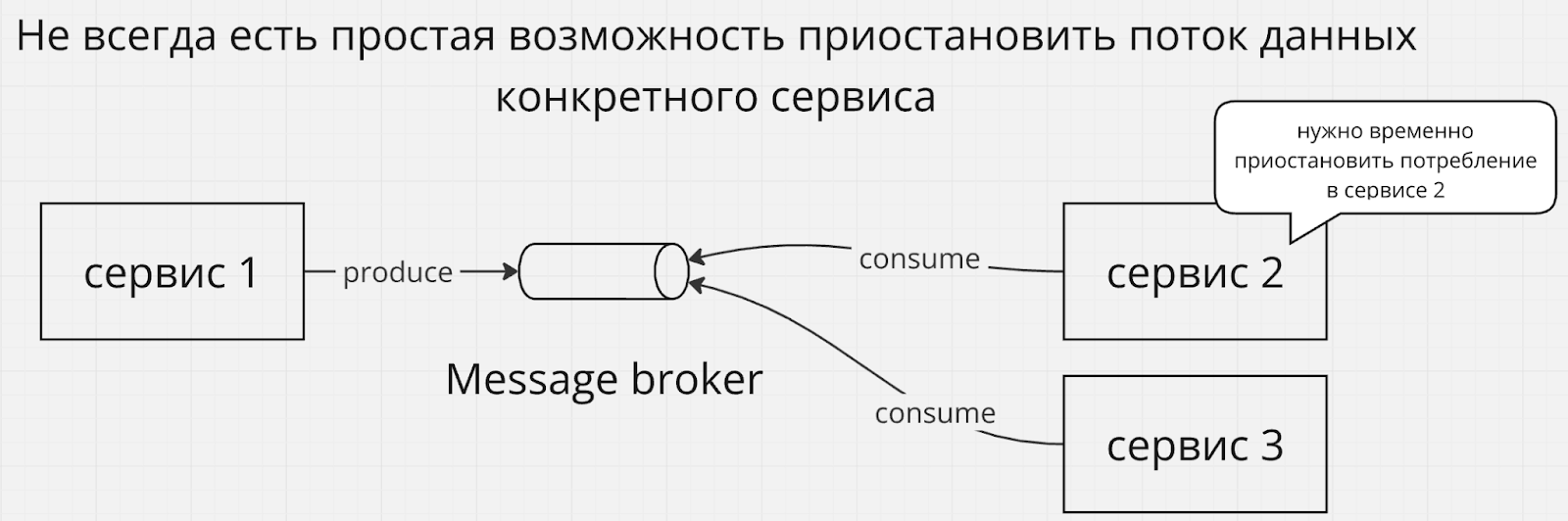
Передавая контроль за потреблением на сторону Nifi вы тем самым получаете возможность остановить конкретный поток данных вручную только для одного сервиса, продолжая передавать данные остальным сервисам.
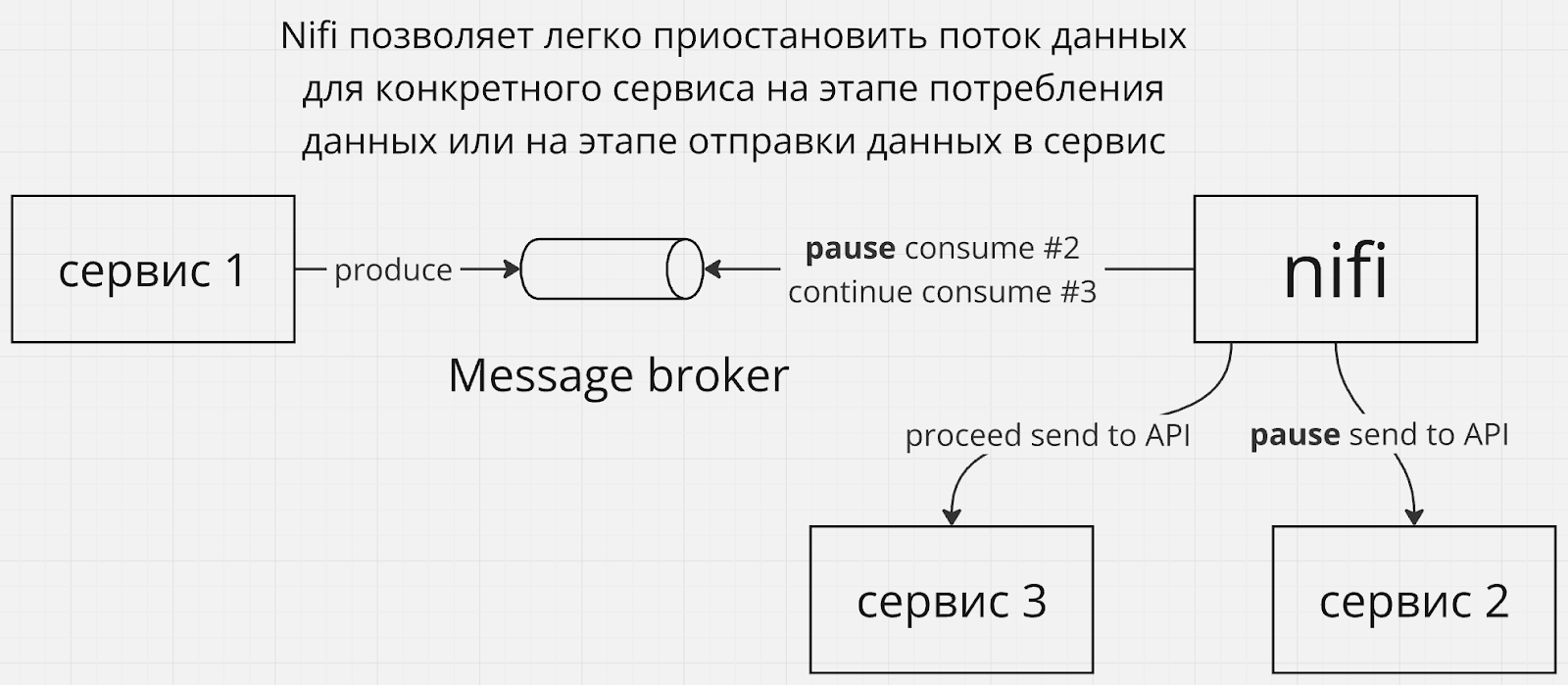
Я бы не стал заносить Nifi в проект только ради одной этой возможности, но это приятный бонус.
Управление неопределенностями
Изменять пайплайны обработки данных в Nifi довольно просто, это можно делать буквально на-лету, что позволяет заниматься разработкой интеграций в условиях сильной неопределенности и/или частых изменений контрактов API.

Использовать с осторожностью
Рассмотрим ситуации в которых, по моему мнению, применение Nifi может быть спорным решением и требовать обсуждения с разработчиками, архитекторами и прочими заинтересованными сторонами. Все что я описываю далее – не стоит воспринимать как к истину в последней инстанции, просто примите к сведению. Каждый проект уникален и требует осознанного подхода, кому-то в вашей команде должны платить деньги именно за то, чтобы задаваться указанными вопросами в контексте конкретных инженерных и архитектурных проблем (и брать на себя ответственность за решения).
Валидация данных в рамках сервисной архитектуры
Валидация может являться серьезной частью бизнес логики. Если это так, то перекладывание этой задачи на Nifi размывает архитектурные границы сервиса, бизнес логика становится размазанной между сервисом и Nifi. Казалось бы, мелочь, но мне кажется, что маленькие нарушения принципов чистой архитектуры развязывают руки для новых нарушений, подобно теории разбитых окон. В результате ваш Nifi будет превращаться в спрута, берущего на себя все больше ответственности, потому что “так удобнее”, а ваша архитектура будет скатываться к тому, что называют “большой комок грязи” (“big ball of mud”). Я предпочитаю руководствоваться принципом “сервисы – для бизнес логики и технической логики, Nifi – только для технической логики”. Задайте себе вопрос: “валидация является важным элементом бизнес процесса, или это техническая валидация для предотвращения дальнейших проблем?”.
Также, если валидация может быть произведена средствами сервиса, возможно там её и стоит производить, а Nifi использовать только в тех случаях, когда для валидации нужна интеграция с несколькими источниками данных, и по соображениям чистой архитектуры вы не хотите создавать такую интеграцию в рамках сервиса:
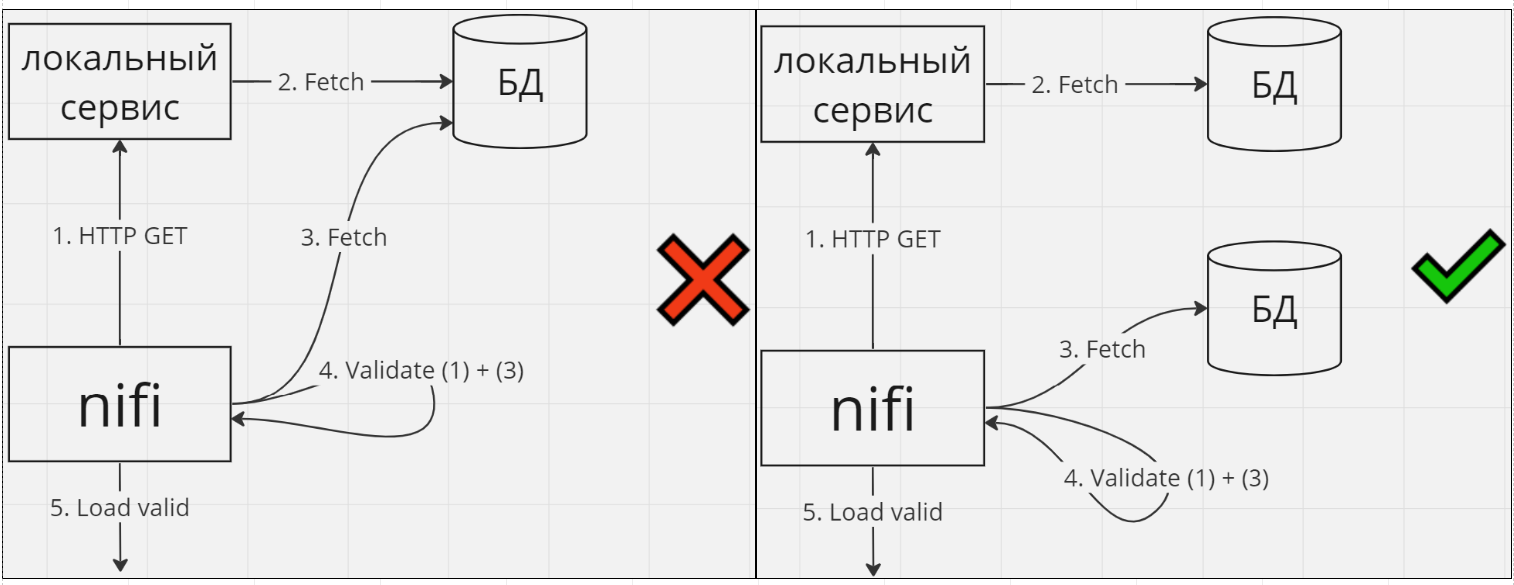
Трансформация данных в рамках сервисной архитектуры
Также как и в предыдущем случае – если семантика трансформации может зависеть от бизнес логики – может быть лучше делать это в сервисе. Опять же, я бы советовал задавать себе вопрос: “Эта трансформация необходима по требованиям бизнес логики, или это просто техническая трансформация для удобства реализации?”.
Например, рассмотрим пример преобразования статусов из одной статусной модели в другую при передаче данных между сервисами. Оправдано ли в таком случае использовать Nifi для преобразования статусов зависит:
- от того, что это за статусы – относятся ли они к бизнес процессу или являются техническими маркерами конкретной технической реализации
- от того относится ли сама трансформация к бизнес процессу, или это техническое преобразование в угоду различиям в именовании статусов в разных сервисах
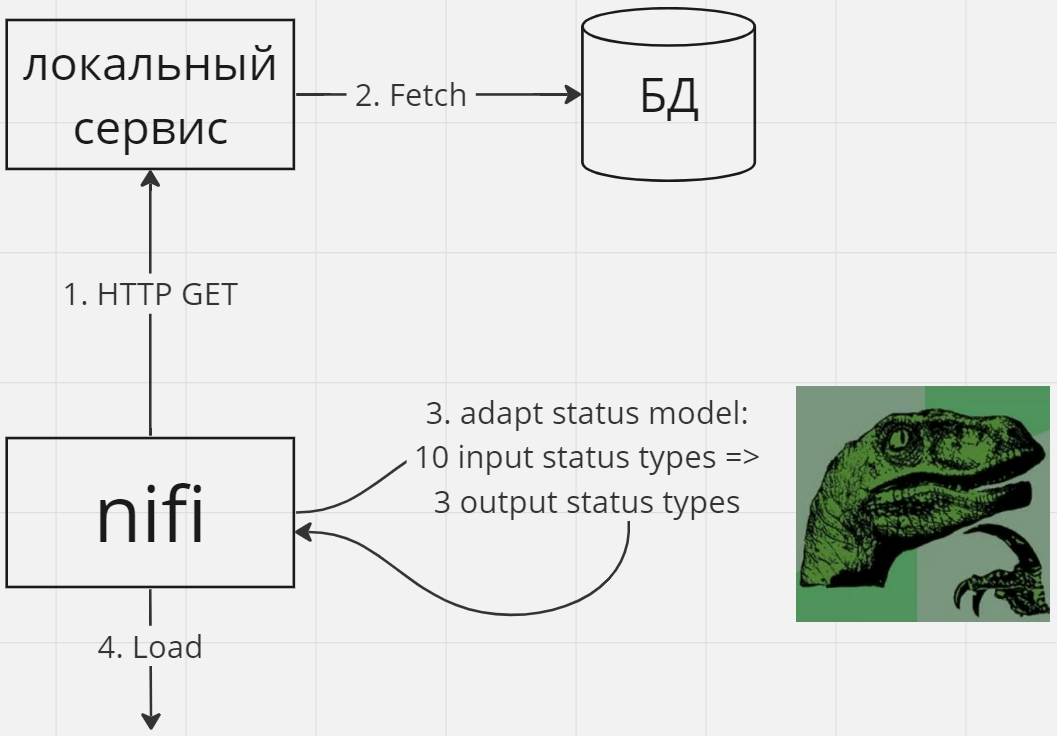
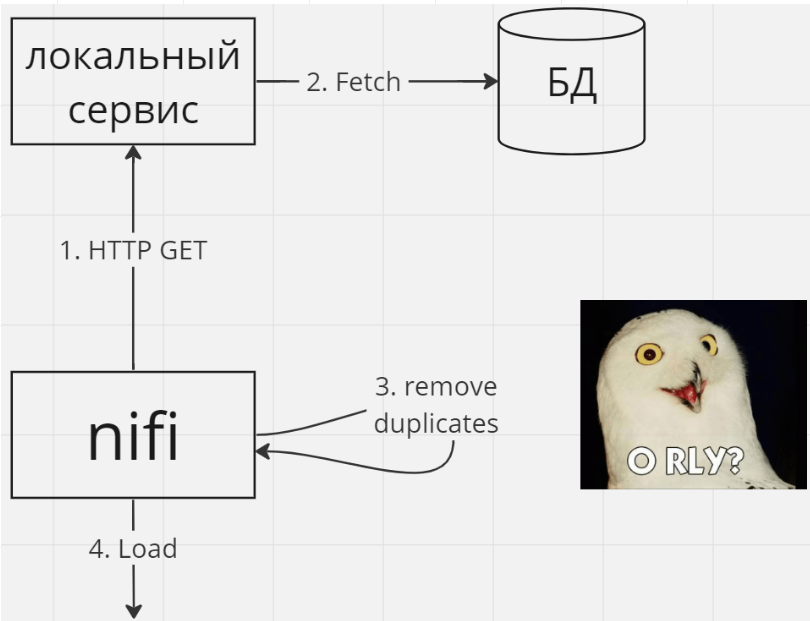
Если трансформация достаточно проста, может быть имеет смысл производить её сразу в сервисе. Например, если вы хотите избавиться от дубликатов, это проще сделать на этапе запроса данных из БД (используя DISTINCT), а не в Nifi, в том числе потому, что на этапе запроса в БД у вас больше контекста (все данные в БД), а на этапе обработки в Nifi контекста меньше (только те данные, которые в данный момент находятся в Nifi).
Nifi как шина (ESB)
Nifi по своим возможностям может выступать в роли сервисной шины, но есть нюанс. Из-за специфики работы с Nifi очень легко временно отключить какой-то процессор, группу процессоров или контроллер (например, для изменения конфигурации или анализа конкретной очереди), забыть включить и парализовать работу "шины".
Для ESB существует множество более специализированных инструментов, стоит изучить целесообразность их использования.
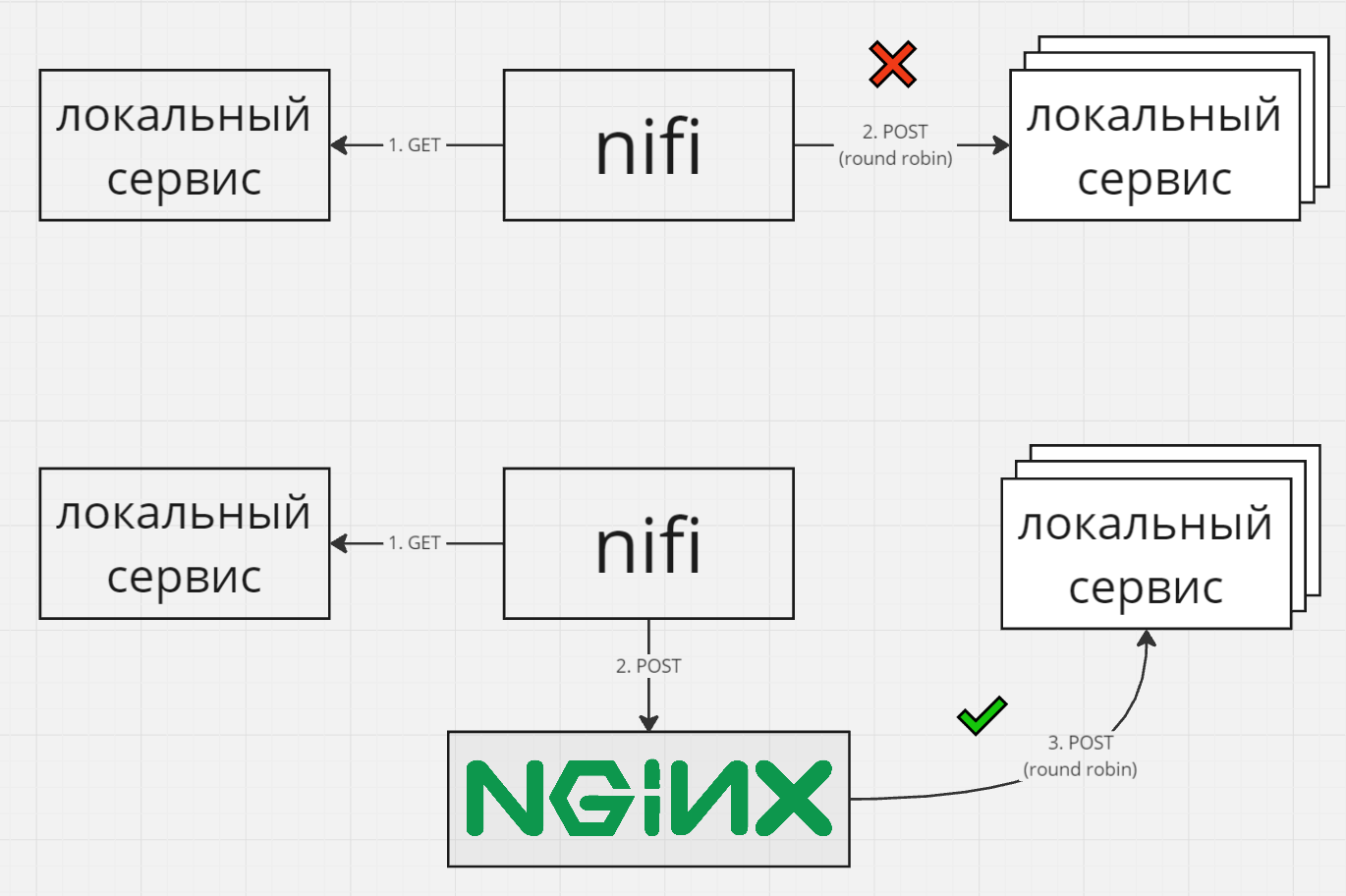
Service-mesh потребности
Service-mesh – это различные инструменты для настройки межсервисного взаимодействия, например балансировка нагрузки, шифрование, лимитирование пропускной способности (bandwidth throttling). Nifi может закрывать некоторые service-mesh потребности. Однако все таки Nifi это прежде всего ETL-инструмент, и для сложных кейсов я рекомендую сразу взять специализированные инструменты для точечного решения отдельных задач или полноценное service mesh решение, которые по определению лучше справятся с задачей или дадут больше вариантов решения.
Автоматизация логики внешнего мониторинга и нотификации
Для простых случаев Nifi можно использовать и для этих целей, но опять же, если есть возможность – возьмите специализированные инструменты.
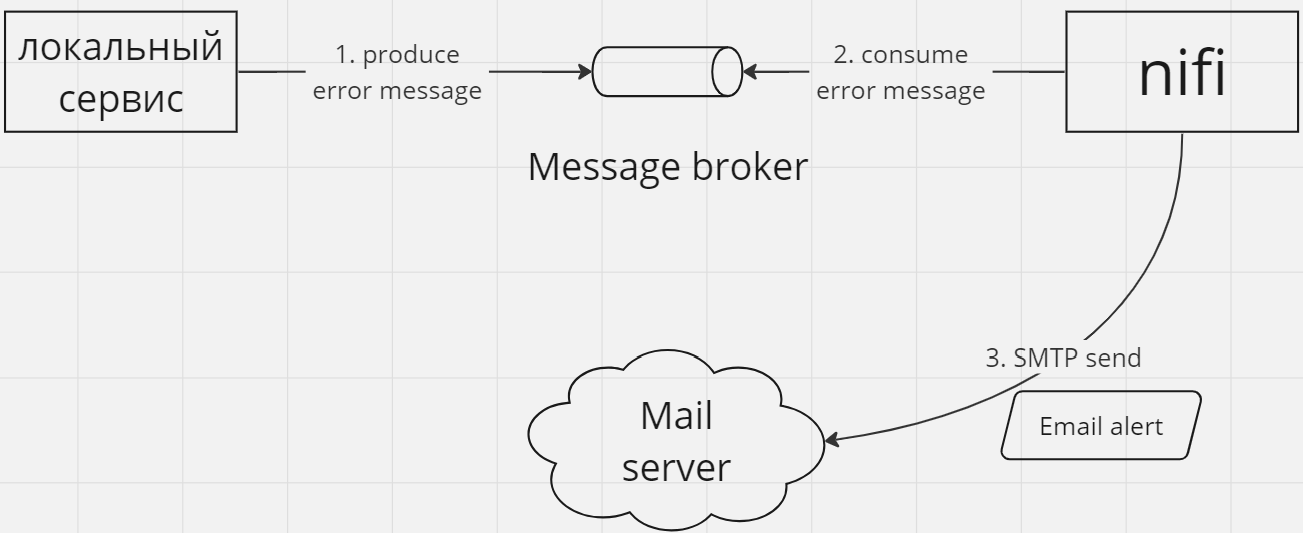
MVP, прототипирование, proof-of-concept
С Nifi можно начинать, если вам важнее быстро выйти на рынок и протестировать жизнеспособность бизнес-плана с MVP, чем вслепую начинать полноценную разработку вашего продукта. Главное вовремя осознать момент целесообразности трансформации, когда Nifi перестает закрывать ваши потребности. Упустив этот момент вы можете столкнуться с повышенной сложностью (и стоимостью) миграции к полноценной разработке.
При таком подходе очень важно понимать все ограничения, риски, сильные и слабые стороны Nifi и целесообразность его использования в вашем бизнесе, такие вопросы должны быть закрыты в рамках совместной работы бизнес аналитика и системного аналитика (или архитектора) до выхода на рынок.
Ручной контроль / анализ большого объема данных "в полёте" и после обработки
Nifi не самая удобная система для полноценного контроля и анализа всей полноты данных, которые проходят или уже прошли через обработку по следующим причинам:
- Nifi не показывает содержимое всей очереди, лишь первые 100 FlowFile-ов без возможности постраничного просмотра.
- Nifi не дает богатого инструментария поиска FlowFile-ов по их атрибутам / контенту, при необходимости вам придется либо настраивать отдельное описание потока данных даже для простой фильтрации очереди для поиска каких-то конкретных данных, либо искать их в истории provenance (при условии что они еще не удалены) используя такие фильтры как FlowFile UUID, диапазон времени когда было зарегистрировано provenance-событие, объем FlowFile, ID компонента в котором произошло событие и т.п.
Nifi вообще не спроектирован как удобное долговременное хранилище данных / событий. FlowFile должен быть обработан как можно скорее и удален, чтобы освободить место другим.
Синхронизация между разными FlowFile-ми
Архитектура Nifi гораздо лучше подходит под такие сценарии обработки, в которых предполагается независимость одних FlowFile-ов от других. Задачи, требующие размазанного состояния данных по нескольким процессорам одновременно или синхронизации обработки между разными FlowFile-ми реализовать в Nifi не так просто.
Часть таких потребностей можно решить с помощью процессора ExecuteStateless [^], (помогает исполнять несколько процессоров в "транзакции", например [^]) или связки процессоров Wait + Notify [^] коммуницирующих через кэш (аналог средств синхронизации конкурирующих потоков).
Также некоторые процессоры могут хранить состояние обработки и удовлетворять потребность в синхронизации в узкоспециализированных операциях, например процессор MergeContent может соединять контент только тех FlowFile-ов, у которых совпадают значения атрибута FlowFile заданного в параметре процессора Correlation Attribute Name. Если ваши FlowFile-ы еще и распределены по нодам кластера, вам придется учитывать, что для подобной синхронизации они должны оказаться на одной и той же ноде.
Хватит ли этих возможностей для вашей ситуации советую изучить заранее.
Динамическое изменение логики обработки
Конфигурация обработки потоков данных в Nifi скорее статична, т.е. сложно реализовать её изменение в runtime. Такие полиморфные паттерны разработки как например “стратегия” или “шаблонный метод”, легко разрабатываемые на любом современном языке программирования высокого уровня, для реализации в Nifi потребуют громоздких конструкций через процессоры ветвления (RouteOnContent, RouteOnAttribute) и интенсивное изменение атрибутов / контента FlowFile-ов. Да и вообще, произвольные алгоритмы с большим количеством ветвлений и циклов гораздо проще реализовать отдельно от Nifi (или в крайнем случае через ExecuteScript).
Также, в Nifi не предусмотрены удобные инструменты переиспользования описаний потоков, подобно тому как мы могли бы переиспользовать разную последовательность и/или набор одних и тех же функций в языках программирования для реализации немного разных алгоритмов. Если вам нужно очень похожее, но немного видоизмененное поведение при обработке двух (или более) потоков данных, выбор у вас небогатый:
- Можно скопировать часть потока (возможно через шаблонизацию или через копирование группы) и настроить его отдельно от оригинала. Но тогда вы получите обособленный дубликат описания потока, который начинает жить своей жизнью. Если в дальнейшем часть общей логики этого потока нужно поменять для всех – вам придется делать это независимо во всех таких скопированных участках.
- Можно воспользоваться NiFi Registry в котором есть возможность версионировать группы [^] [^] и создавать несколько отдельных “экземпляров” таких групп по одному и тому же описанию. Но если какие то части потока этой группы нужно будет изменить для каждого экземпляра группы своим отдельным образом, получается, что либо вам придется отказаться от их дальнейшей синхронизации через NiFi Registry, либо делать поток очень рваным – его общие части должны управляться через Registry, а уникальные участки – нет.
- Можно создать единый поток для общей обработки и каким-то образом поддерживать понимание о том, от какой родительской ветки пришли FlowFile-ы (например определяя атрибут-идентификатор потока через UpdateAttribute), как должна измениться логика для конкретного потока (например через ветвление по атрибуту с помощью RouteOnAttribute) и куда они должны вернуться (опять же через ветвление RouteOnAttribute в конце). Но при этом общие участки описания потока становятся бутылочными горлышками, т.к. они пропускают через себя все FlowFile-ы из всех родительских потоков. Конечно, до какого-то момента вам может помочь параллельная обработка на нескольких jvm-thread-ах или распределение нагрузки на ноды в кластере, но если все таки в какой-то момент забьется очередь на общем участке – обработка замедлится для всех родительских потоков.
- Можно реализовать (3) через Nifi Registry как это предлагается в (2), таким образом взяв лучшее из этих двух подходов. Но тогда создавая отдельные “экземпляры” групп под каждый родительский поток вы тем самым оставляете все альтернативные ветки для других родительских потоков инертными, т.к. конкретный родительский поток может никогда их не использовать в данном экземпляре. В результате может усложниться понимание настроенной логики другими инженерами.
Если говорить про конфигурационные параметры – их можно варьировать через переменные и через Nifi Parameter Contexts. Ограниченная вариативность обработки может быть настроена с помощью контроллеров.
В следующей статье я расскажу, когда использовать NiFi — плохая идея. Покажу, к чему приводит перенос бизнес-логики в NiFi, и почему в enterprise-проектах это особенно рискованно. Разберу реальные проблемы, с которыми я сталкивался: баги процессоров, нюансы работы кластера, ошибки конфигурации и ограниченные возможности.





