Привет, я Антон, backend-разработчик в CosySoft. В этом цикле статей я расскажу про Apache NiFi — инструмент для работы с потоками данных, который мы используем в проекте.
Таких статей в интернете много, но эта – моя. Здесь будет обзор основных возможностей, плюсы, минусы, советы по использованию с точки зрения IT-инженера, использующего Nifi в своем проекте – backend-разработчика, системного аналитика, тестировщика, архитектора. Если вы хотите быстро вникнуть в тему и не тратить время на десятки вкладок, эта статья — для вас.
В первой части пойдет речь о том, что такое Apache NiFi и какие задачи он решает, как он вписывается в общую архитектуру ETL-инструментов, чем удобен как визуальный конструктор конвейеров.
Администрирование и конфигурирование подробно не рассматриваются в статье. Сравнение с другими похожими системами не рассматриваются. Надстройки над Apache Nifi (вроде Kylo) не рассматриваются. От читателя ожидается наличие опыта уровня middle и выше, общего понимания сферы разработки распределенных backend-систем (прежде всего, знакомства с основными терминами и технологиями).
Что такое Apache Nifi и какие задачи он решает
Apache Nifi как ETL инструмент
Прежде всего, Apache Nifi следует рассматривать как ETL инструмент. ETL инструменты представлены широким набором самых разных решений, как open-source так и проприетарных, довольно разнообразных по виду и возможностям. Но все они в том или ином виде позволяют вам автоматизировать следующий процесс:
- Извлечь данные из некоторого источника (Extract)
- Изменить эти данные некоторым способом (Transform)
- Передать измененные данные некоторому потребителю (Load)
Источниками и потребителями как правило являются web-сервисы и информационные системы, файловые системы, базы данных, брокеры сообщений и т.п.
Пример решаемой задачи
Представьте себе следующее техническое задание из мира бекенда. У вас есть два источника данных – брокер сообщений (очередь) и API внешнего сервиса. Вам нужно сохранить данные из очереди в некотором готовом микросервисе с реляционной базой данных. Также, данные из очереди и из внешнего сервиса в агрегированном виде нужно сохранить в колоночную базу данных для OLAP, но проблема в том, что пока нет никакого реализованного микросервиса, связанного с этой колоночной базой, и возможности автоматической интеграции между базой и очередью тоже нет. Вам также сообщают, что в будущем эта схема может эволюционировать – у вас может появиться больше разнородных источников данных и больше потребителей, логика маршрутизации, агрегации и прочей обработки этих данных может усложниться.
Налицо несколько задач и проблем, о которых нужно подумать, если решать задачу “в лоб”.
Нужно разным способом собирать и обрабатывать данные для двух потребителей – для микросервиса требуется простое получение данных из очереди и сохранение, для OLAP – агрегация. Для OLAP также придется реализовать микросервис, который потребляет данные из очереди, дозапрашивает информацию из внешнего сервиса, и при успешной агрегации сохраняет данные в колоночную базу.
Возникает куча нюансов и деталей реализации. Например, рассмотрим микросервис агрегации для OLAP. Что делать при неудаче агрегации – наверняка понадобится механизм повторных попыток для неудачных сущностей (или после недоступности внешнего сервиса) или хотя бы некий сбор таких неудач и уведомление о них. Наверняка обращение к внешнему сервису будет дорогой операцией, следовательно нужно будет накапливать данные из очереди в некий буфер и запрашивать данные внешнего сервиса для нескольких сущностей одновременно, если API внешнего сервиса позволяет это сделать. Значит, агрегация будет происходить через запускаемую по расписанию задачу в асинхронном режиме. Это влечет необходимость управления этими запусками, а также решения вопроса синхронизации – если этот сервис запускается на кластере в нескольких экземплярах, нужно реализовать все так, чтобы исключить обработку одних и тех же сущностей одновременно на нескольких нодах – через балансировку, блокировки, или выбор одного экземпляра приложения (leader election), которому будет разрешено заниматься обработкой (с решением проблемы динамического увеличения или уменьшения количества нод). И так далее. Конечно, вам не придется все это писать с нуля, это типовые задачи решенные до вас, и к тому же не одним способом. Тем не менее, собрать этот конструктор придется.
С архитектурной точки зрения тоже есть проблемы. Если будет возрастать количество источников данных, это означает, что нужно будет добавлять логику приема этих данных в оба микросервиса. Рост количества источников принесет дополнительные проблемы – у микросервисов растет количество зависимостей от этих источников (увеличивая потребность в постоянном сопровождении этих микросервисов, если формат данных будет меняться) и увеличивается нагрузка на микросервисы. Логика обработки этих потоков данных получается размазанной по множеству микросервисов, что усложняет ее общее понимание архитекторами и разработчиками и создает проблемы организационного плана. Например, если за микросервис с реляционной БД и за микросервис с колоночной БД будут отвечать разные команды разработки, вы получите еще и проблему синхронизации работы этих команд и совместных релизов, т.к. при изменении формата источника данных изменения нужно будет вносить синхронно. Появление новых потребителей, как в случае с колоночной БД, может потребовать реализации новых микросервисов-оберток, не нужных ни для чего другого, но требующих усилий по разработке и сопровождению.
Могут появиться и другие потребности. Например, может потребоваться функция ручного просмотра истории и просмотра текущего процесса обработки данных, а также способы ручного управления этой обработкой в случае возникновения проблем. А если вы работаете в организациях с повышенным режимом информационной безопасности, вам еще и наверняка придется решать проблему политики нулевого доверия – управлять правами доступа, вести журналы событий, шифровать данные по пути их передачи от потребителя к получателю и т.д.
Было бы здорово иметь платформу, берущую на себя централизованное решение перечисленных проблем, не правда ли? Конечно, можно пойти по пути написания собственного централизованного сервиса для этих целей, но представьте себе объем работы и требования к компетенциям при разработке такого решения, с учетом того, что это должен быть сервис повышенной надежности, с возможностью масштабироваться под возрастающий поток данных и т.д. К счастью, вам не нужно придумывать велосипед, есть множество готовых ETL решений, Nifi один из них.
Общая архитектура ETL инструментов
Если совсем упрощенно, ETL инструмент обычно состоит из трех основных модулей – коннекторов (отвечают за Extract и Load, например средство подключения к базе данных или брокеру сообщений), трансформаторов (отвечают за Transform, например реализуют логику замены текста по шаблону) и некоторого описания потока данных – списка правил по которым данные извлекаются, трансформируются и передаются потребителю.
Обычно, ETL инструмент предоставляет готовую реализацию коннекторов и трансформаторов, а от вас требуется предоставить конфигурацию для них (например, url-адрес и реквизиты доступа для коннектора к базе данных, настройки алгоритма трансформации данных), а также определить описание потока данных – то, из какого коннектора ETL инструмент будет получать данные, с помощью каких трансформаторов он будет их менять (и будет ли вообще это делать) и в какой коннектор он будет их выгружать (и будет ли вообще это делать).
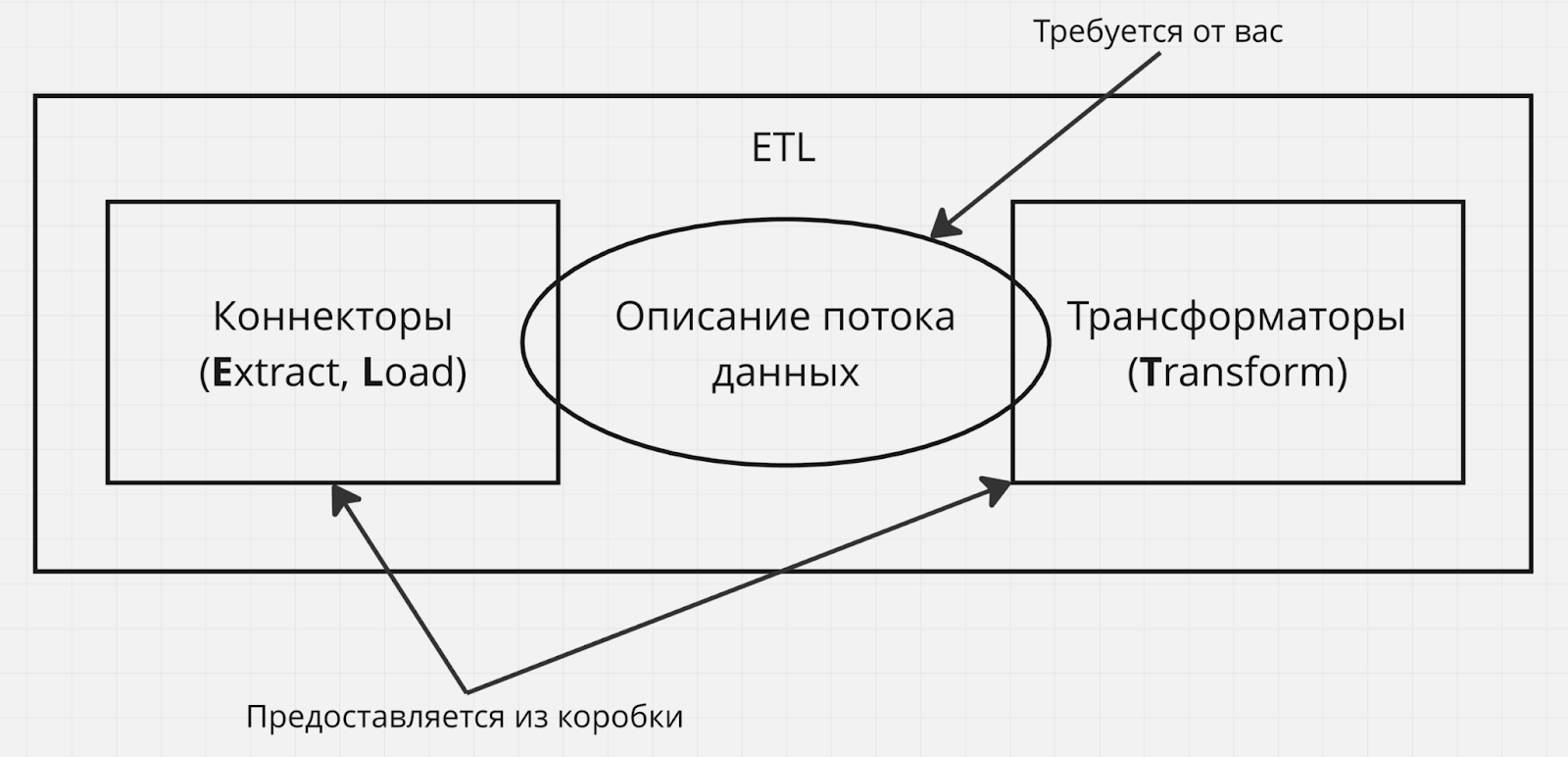
Виды ETL инструментов
Подробный обзор и классификация ETL инструментов выходит за рамки этой статьи, но полезно рассмотреть два основных вида ETL инструментов, на которые их можно разделить – я называю их скриптовыми и визуальными.
Скриптовые ETL инструменты
Подобные ETL инструменты представлены некоторым программным фреймворком. Коннекторы представлены в виде готовых программных классов, интерфейсов или функций и средств их конфигурирования. Трансформаторы представлены в виде классов и функций преобразования данных. От вас требуется написать программный код, описывающий поток данных, манипулируя готовыми компонентами (коннекторами и трансформаторами).
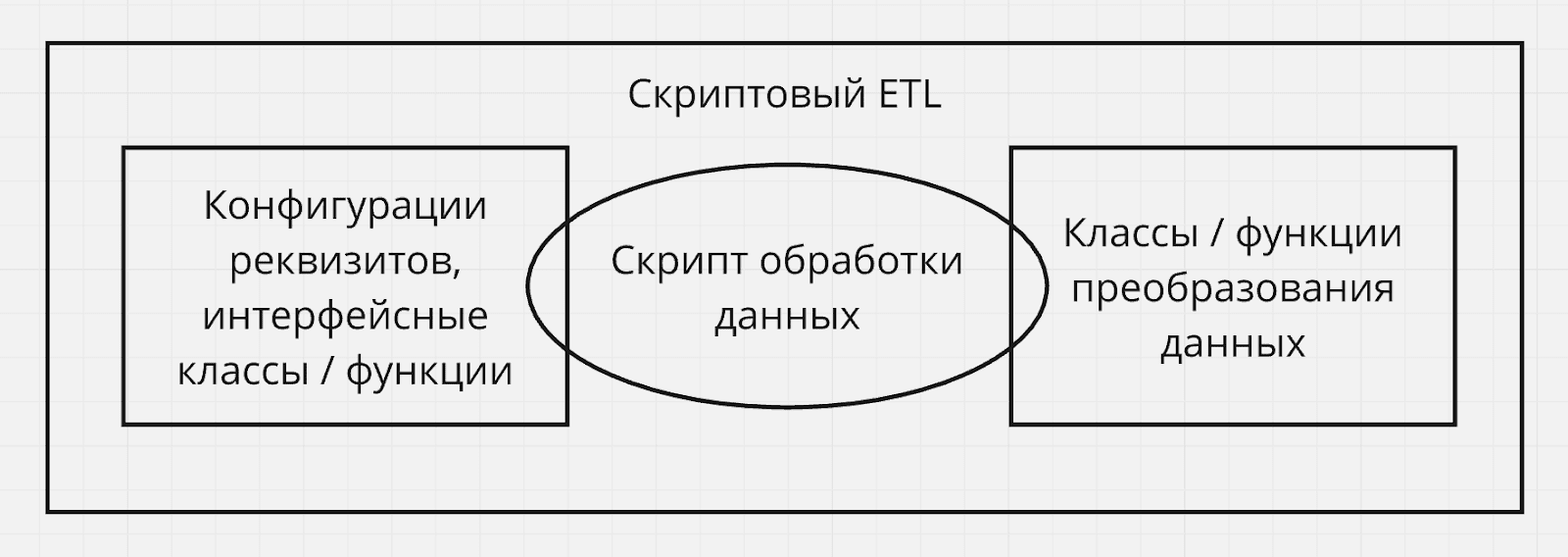
Преимуществом скриптовых ETL мне видится прежде всего широкая свобода и контроль реализации потока обработки данных. Как правило, вы не ограничены библиотеками ETL инструмента, при необходимости вы можете импортировать сторонние библиотеки для узкоспециализированных задач.
Минусом скриптовых ETL является необходимость наличия навыков программирования для конкретного языка, а также повышенная вероятность багов из-за ручной реализации.
Пример – Apache Airflow, который является платформой исполнения скриптов обработки данных на языке Python и содержит обширную библиотеку готовых компонентов, помогающих в этой обработке. Airflow реализует особый шаблон проектирования, заставляющий вас создавать поток обработки данных в виде ориентированного ациклического графа из отдельных задач, каждая из которых представляет этап обработки данных. Airflow также предоставляет web UI управления и мониторинга для удобной работы с вашими потоками данных.
Визуальные ETL инструменты
Визуальные ETL – это платформы, конфигурацию в которых вы производите через UI. Вся техническая реализация скрыта от вас за визуальными абстракциями и черными ящиками, написание полноценного кода обработки данных с вашей стороны практически не требуется, если только вы не хотите расширить внутреннюю реализацию open-source ETL инструмента в очень специфических ситуациях.
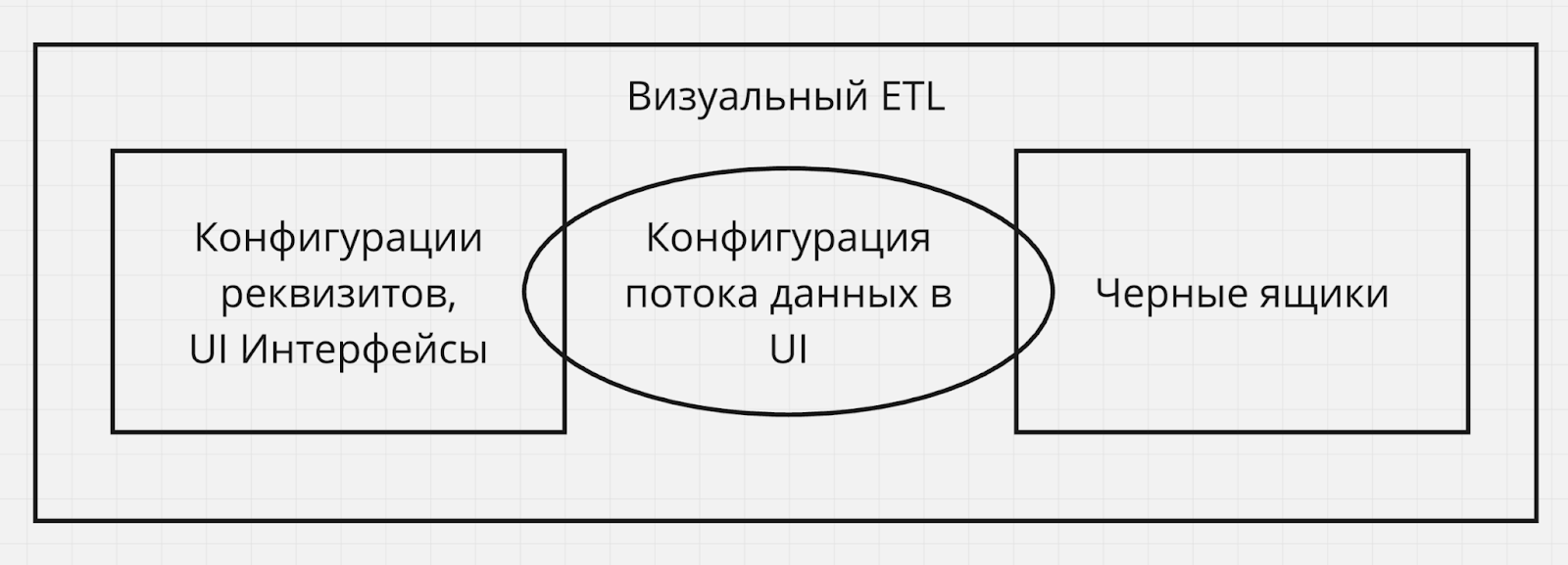
Преимуществом визуальных ETL является высокий уровень абстракции – вам не нужно обладать глубокими навыками программирования в определенном языке, но все же потребуется техническое понимание конкретных используемых информационных процессов, протоколов, API, domain-specific languages и т.п. Также плюсом является тот факт, что готовая техническая реализация практически всех компонентов ETL процесса дает предсказуемость и надежность.
Минус – меньшая гибкость и свобода реализации процесса. Вы ограничены тем, что предоставляет ETL инструмент, а доработка его технической реализации (если это open-source) или плагинов может потребовать более глубокого изучения принципов работы самой ETL платформы и наличия определенного уровня экспертизы в выбранных разработчиками паттернах и решениях.
Apache Nifi – визуальный ETL инструмент.
Минус – меньшая гибкость и свобода реализации процесса. Вы ограничены тем, что предоставляет ETL инструмент, а доработка его технической реализации (если это open-source) или плагинов может потребовать более глубокого изучения принципов работы самой ETL платформы и наличия определенного уровня экспертизы в выбранных разработчиками паттернах и решениях.
Apache Nifi – визуальный ETL инструмент.
Apache Nifi как конструктор конвейеров обработки данных
Ознакомившись с Apache Nifi вы быстро обнаружите, что в основе шаблона проектирования описания потока данных лежит идея pipeline архитектуры – данные передаются по очередям от источника к потребителю через ряд промежуточных обработчиков. В результате большую часть времени вы проводите за составлением этого конвейера обработки данных, который может ветвиться, соединять несколько веток в одну и даже образовывать петли. Ваша задача также – выбрать подходящие компоненты-обработчики (коннекторы, трансформаторы) для каждого желаемого этапа обработки и сконфигурировать их под ваши нужды.
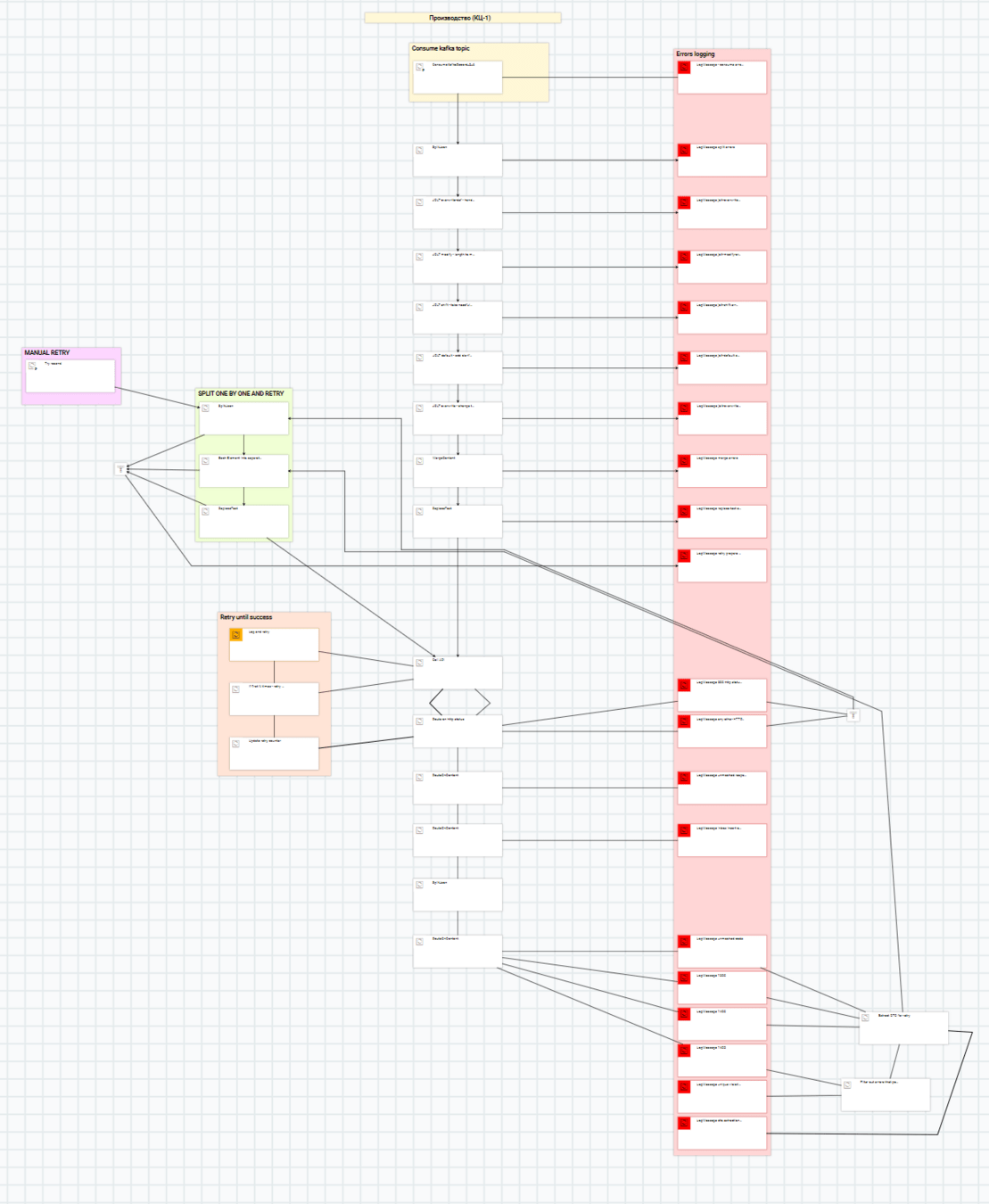
Один из потоков Nifi c моего проекта. Сейчас нет смысла всматриваться в детали,просто заметьте, что это очень похоже на ориентированный граф с циклами
Совсем краткая история появления Apache Nifi
В истории технологического прогресса неоднократно бывало так, что сначала продукт разрабатывался для военных / силовиков, а затем передавался в гражданскую сферу чтобы приносить пользу народному хозяйству. Забавно, что Apache Nifi прошел похожий путь.
Акроним “Nifi“ образован из названия “NiagaraFiles”. Система NiagaraFiles была разработана в закрытом режиме для внутренних нужд Агентства Национальной Безопасности США, первый релиз – 2006 год. В рамках программы передачи технологий АНБ в 2014 году на основе NiagaraFiles был создан open-source Apache Nifi.
Интересно, что NiagaraFiles сразу создавался с предположением, что возможно в будущем он будет выпущен под открытой лицензией [^]. Аттракцион неслыханной щедрости.
Архитектура Apache Nifi
Nifi можно разворачивать в двух режимах – в режиме отдельного приложения (standalone) или в режиме кластера из нескольких экземпляров, синхронизируемых через Zookeeper.
Standalone режим
Этот режим работы подходит под обработку небольших объемов данных (порядка нескольких сотен мегабайт в секунду или меньше). Также он полезен для развертывания на ПК IT-инженеров для локальных экспериментов.
Вам понадобится окружение с операционной системой, поддерживающей Java Virtual Machine (Nifi написан на Java). Обычно это небольшой сервер с серверной ОС, виртуальная ОС или среда с поддержкой контейнеризации (например, ОС c поддержкой Docker).
Взгляните на общую схему архитектуры Nifi из официальной документации [^]:
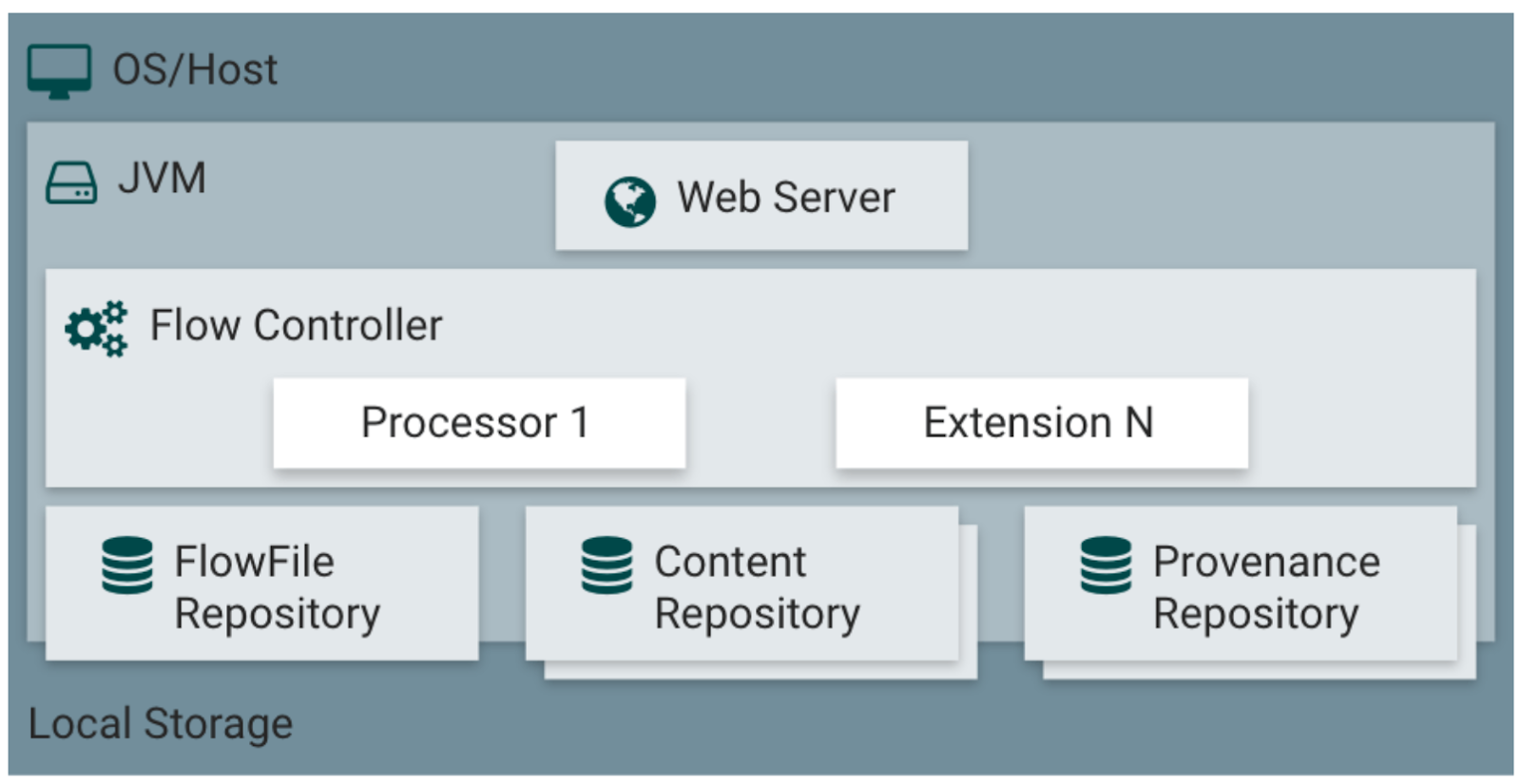
Кратко опишем компоненты с этой схемы:
- Web Server – интерфейс пользователя и HTTP API управления потоками данных.
- Flow Controller – управляет программными потоками (threads), предоставляя их для выполнения работы модулям коннекторов, трансформаторов (Processors / Процессоры в терминах Nifi) и прочих расширений (Extensions, например системы сбора статистики, аутентификации и авторизации и т.д.).
- FlowFile Repository – абстракция над хранилищем мета-информации о данных (данные в Nifi упакованы в специальную абстракцию – FlowFile), текущих по потокам данных. Мета-информация представлена как данными, заполняемыми самим Nifi (идентификатор, дата создания и проч.) так и теми данными, которые вы сами захотите записать в мета-информацию. Позже мы рассмотрим как это работает подробнее. Сейчас достаточно сказать, что конкретная реализация хранилища может быть настроена как плагин, по умолчанию это Write-Ahead-Log файлы на указанной партиции (partition) диска.
- Content Repository – абстракция над хранилищем непосредственно тех данных, которые обрабатываются настроенными потоками данных. В отличие от короткой метаинформации в FlowFile Repository, Content Repository может содержать для каждого FlowFile любой объем связанных с ним данных, которые вы прочитали из коннектора (или создали с нуля). Позже мы рассмотрим как это работает подробнее. Сейчас достаточно сказать, что конкретная реализация хранилища может быть настроена как плагин, по умолчанию это файлы в файловой системе.
- Provenance Repository – абстракция над хранилищем записей о provenance-событиях, формирующих историю обработки данных, текущих по потокам данных (например “такой-то FlowFile создан в процессоре №1”, “клонирован в процессоре №2”, “уничтожен в процессоре №3”). Конкретная реализация хранилища может быть настроена как плагин, по умолчанию это один или несколько томов (volumes) диска.
Режим кластера
Режим горизонтального масштабирования для обработки больших объемов данных. Взгляните на схему [^]:
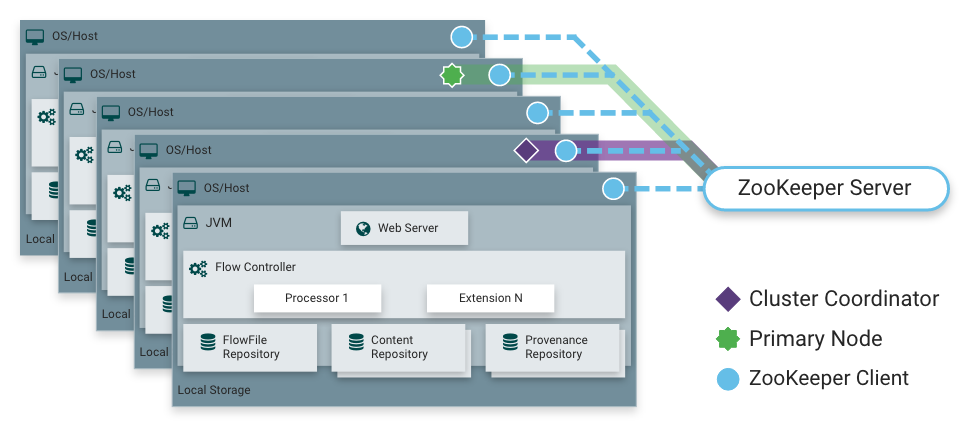
В этом режиме все экземпляры Nifi содержат одинаковую конфигурацию, и поток данных можно разделить без дублирования между этими экземплярами для параллельной обработки – каждая нода выполняет одинаковую работу, но над разным множеством данных. ZooKeeper выбирает одну из нод для координации (Cluster Coordinator), которая занимается такими вещами как проверка и допуск новых нод к обработке данных, предоставление подключаемым новым нодам последнего актуального потока данных и отключение нод, которые перестали присылать heartbeat-сигналы [^]. Также, ZooKeeper выбирает одну из нод в качестве главной (Primary Node), которая может использоваться в тех случаях, когда выполнение определенных задач обработки не желательно производить параллельно на всех нодах. В этом случае вы можете сконфигурировать определенные этапы обработки так, чтобы они выполнялись только на этой одной главной ноде, при этом ваш поток данных со всех нод будет пересылаться на Primary Node и обрабатываться там, после чего его можно снова распределить по всем нодам кластера [^].
С точки зрения UX нет существенной разницы, в каком из этих двух режимов вы работаете – в режиме кластера фактически пользователь работает через UI со случайной нодой, но все изменения настроек и описания потока данных реплицируются на все ноды в кластере [^]. При этом пользователь может обозревать текущую телеметрию и данные, обрабатываемые в реальном времени со всех нод одновременно. Конечно, есть отличия настройки потока данных для кластера от настроек для standalone в силу особенностей распределенных вычислений, об этом поговорим чуть позже, в разделах Relationship и Кластер и его особенности.
Также важно отметить, что каждый отдельный экземпляр Nifi сам по себе может быть сконфигурирован так, чтобы заниматься обработкой своего потока данных параллельно в нескольких программных потоках (JVM-threads). Таким образом, параллельная обработка данных доступна в обоих режимах, разница заключается в объемах данных в единицу времени, которых можно достичь.
С точки зрения UX нет существенной разницы, в каком из этих двух режимов вы работаете – в режиме кластера фактически пользователь работает через UI со случайной нодой, но все изменения настроек и описания потока данных реплицируются на все ноды в кластере [^]. При этом пользователь может обозревать текущую телеметрию и данные, обрабатываемые в реальном времени со всех нод одновременно. Конечно, есть отличия настройки потока данных для кластера от настроек для standalone в силу особенностей распределенных вычислений, об этом поговорим чуть позже, в разделах Relationship и Кластер и его особенности.
Также важно отметить, что каждый отдельный экземпляр Nifi сам по себе может быть сконфигурирован так, чтобы заниматься обработкой своего потока данных параллельно в нескольких программных потоках (JVM-threads). Таким образом, параллельная обработка данных доступна в обоих режимах, разница заключается в объемах данных в единицу времени, которых можно достичь.
Основные понятия Apache Nifi
До сих пор я намеренно старался не использовать специфическую терминологию Nifi и мы не слишком глубоко касались вопроса чем пользователю Nifi приходится оперировать для настройки потоков данных. Пришло время рассмотреть, что из себя представляет Nifi, когда он оказывается у вас в руках.
FlowFile
FlowFile – это абстракция над обрабатываемыми в Nifi данными [^], подобно тому как например HTTP-сообщение является абстракцией над данными, передаваемыми в рамках HTTP протокола по сети.
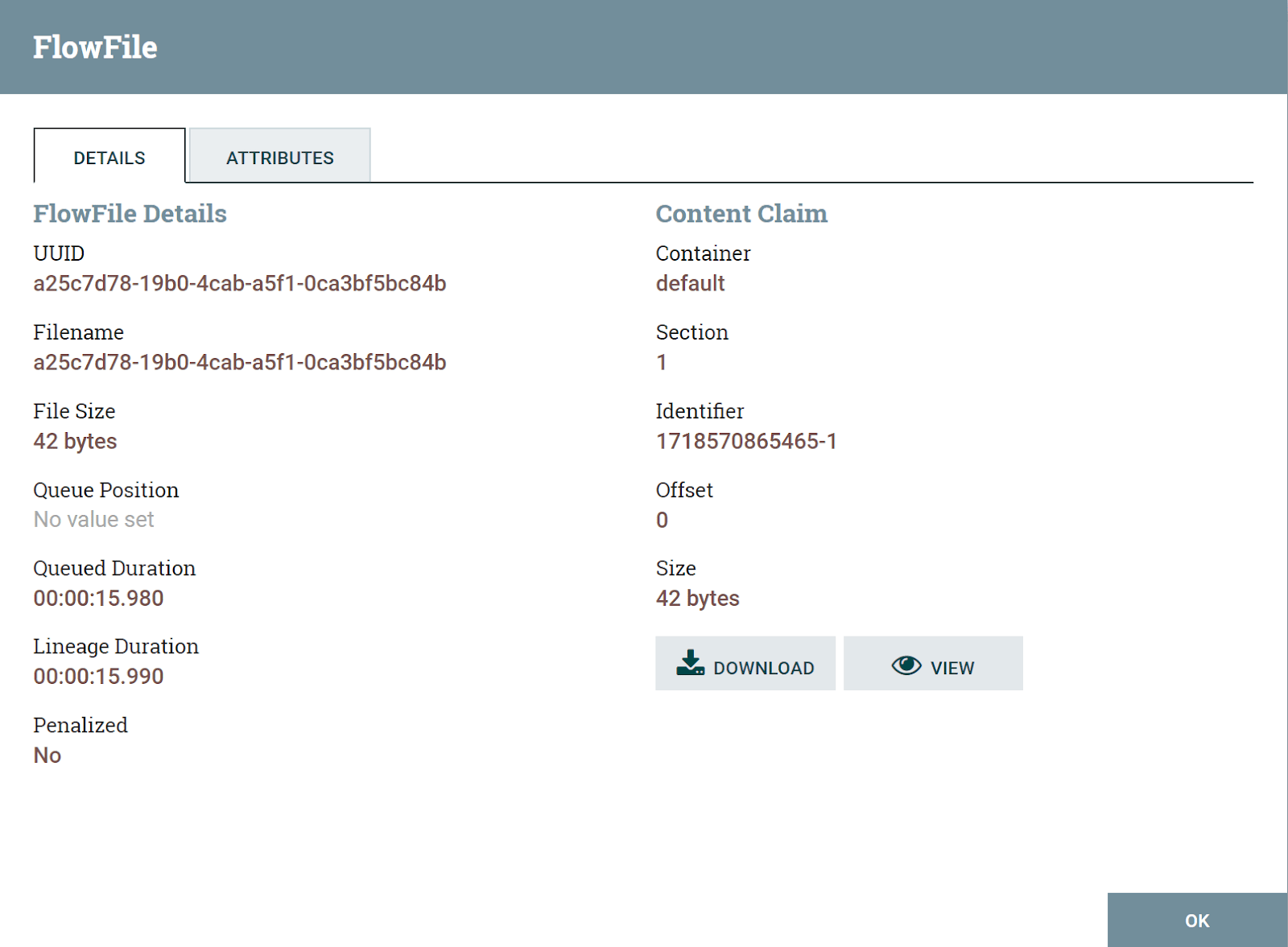
FlowFile это тот единственный элемент, который путешествует по вашему конвейеру обработки данных и является объектом обработки в обработчиках данных (в терминологии Nifi – процессорах).
FlowFile состоит из контента (content) и списка атрибутов (attributes).
Атрибуты – это пары ключ-значение, в которых хранятся как обязательная мета-информация которая есть у каждого FlowFile (идентификатор, дата создания и т.п.) так и те данные, которые туда записываются в ходе обработки. Некоторые атрибуты в FlowFile записываются только определенными процессорами (например, FlowFile-ы появляющиеся в результате потребления данных из Kafka в специализированном процессоре-потребителе, будут содержать атрибуты, специфические для метаинформации сообщения Kafka, например kafka.offset, kafka.partition и т.п.). Также некоторые процессоры позволяют самому пользователю сконфигурировать, какие данные, откуда и в каком виде записываются в атрибуты FlowFile.
Контент – это сами данные в виде массива байтов. Чаще всего это текстовые данные в определенном формате, например JSON, но в общем то это может быть что угодно, в том числе файлы любого формата. Также контент может быть пустым, если например FlowFile является простым сигналом, не требующем наличия данных или если вся его полезная нагрузка умещается в атрибутах.
Сам FlowFile как целое в ходе обработки может быть создан, удален, реплицирован, модифицирован, заменен.
В ходе обработки у FlowFile может поменяться:
- Контент (в том числе он может появиться или наоборот очиститься)
- Значения конкретных атрибутов
- Список атрибутов (атрибуты могут добавляться и удаляться)
Relationship
Relationship – отношения, или, лучше сказать, соединения, это "каналы" по которым текут FlowFile-ы между процессорами, их можно сравнить с лентой конвейера.
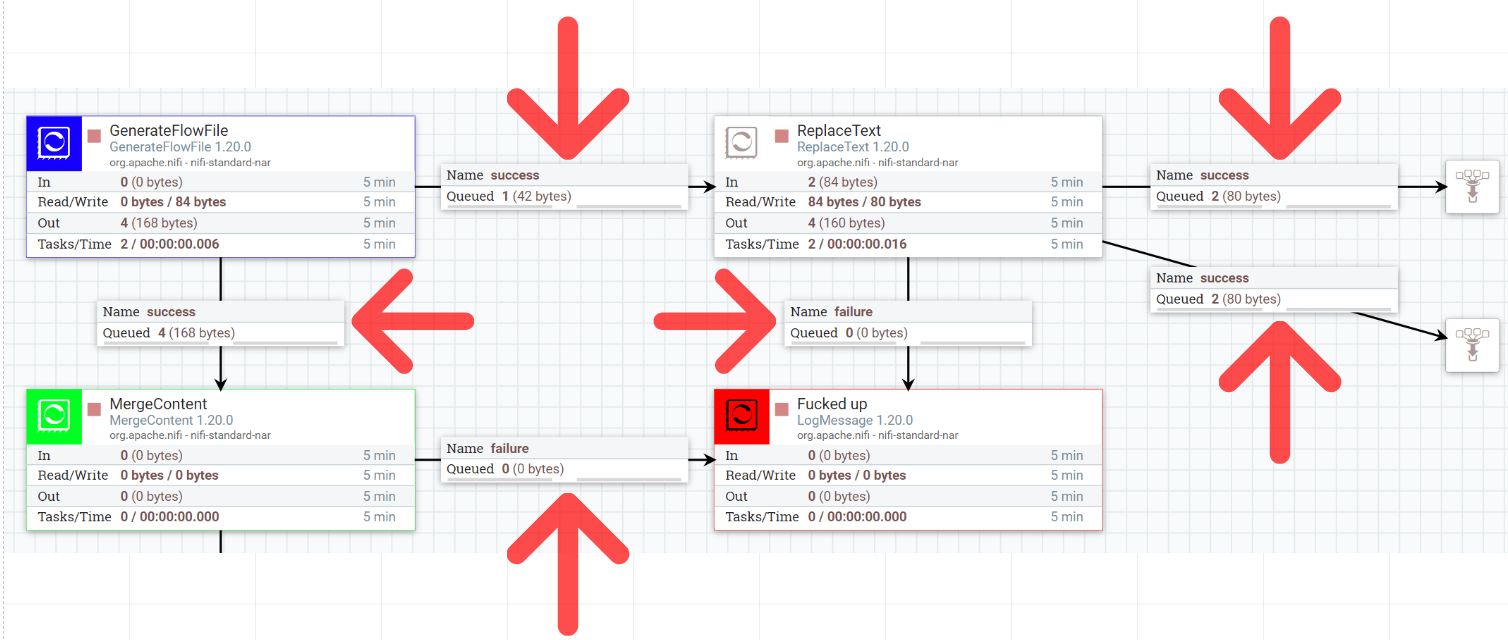
Каждое такое соединение является отдельной очередью и может содержать уникальные настройки. Для каждого соединения-очереди или воронки (точки сбора FlowFile-ов из нескольких соединений в одну общую очередь) можно настроить:
- Приоритет FlowFile-ов в очереди
- Время жизни FlowFile-ов в очереди
- Верхнюю границу по количеству FlowFile-ов или по объему данных FlowFile-ов, при достижении которой включается back pressure очереди
- Балансировку между Nifi-нодами в кластере (+ компрессию) [^]. Заметьте, что по-умолчанию Nifi не будет распределять FlowFile-ы из одного соединения на все ноды, это нужно включить явно. Но не следует включать распределение в каждом соединении, достаточно сделать это один раз где то в начале потока, и по необходимости включать распределение повторно после обработки на Primary Node.
Пользователю доступен просмотр первых 100 (согласно приоритету) FlowFile-ов в каждой очереди через UI [^]. Причем, если Nifi развернут в режиме кластера, вы увидите 100 / N FlowFile-ов из каждой ноды кластера, где N – количество нод (например, для 3 нод вы увидите 33 FlowFile-a из первой ноды, 33 из второй и 34 из третьей). Постраничный просмотр недоступен.
Соединение-очередь можно открепить от одного destination-компонента и перенести на другой компонент без очищения очереди.
Processor
Процессор производит некую узко-специализированную работу над одним или несколькими FlowFile-ми (либо создает их).
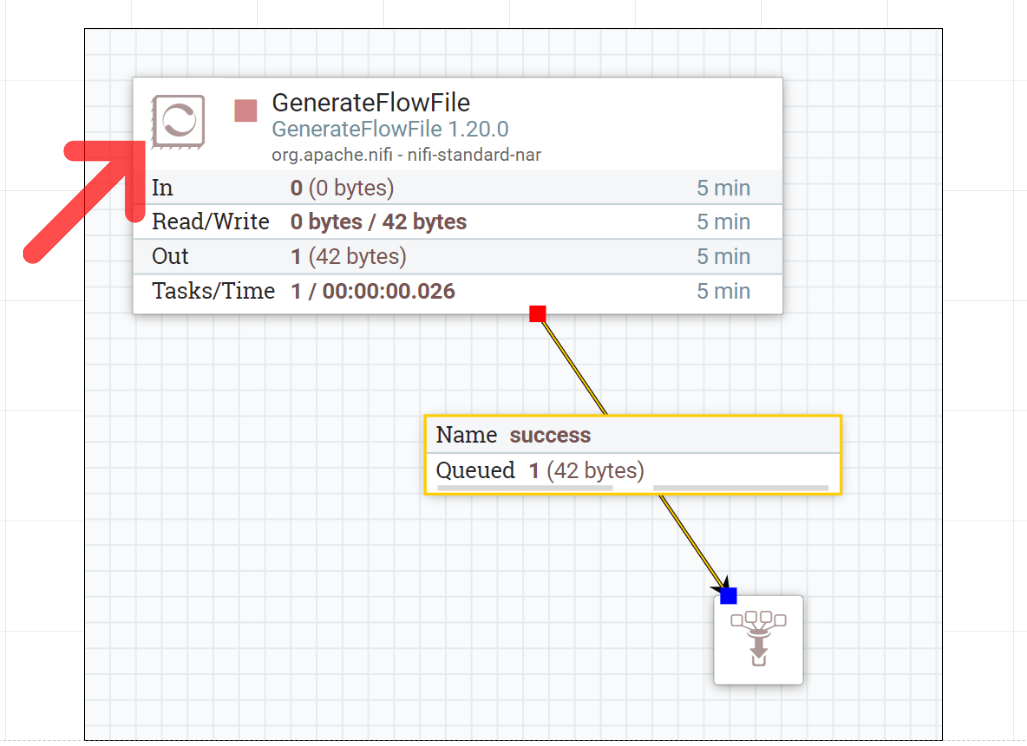
В Nifi существует несколько сотен готовых процессоров, каждый из которых заточен для определенной задачи. Типичные примеры процессоров:
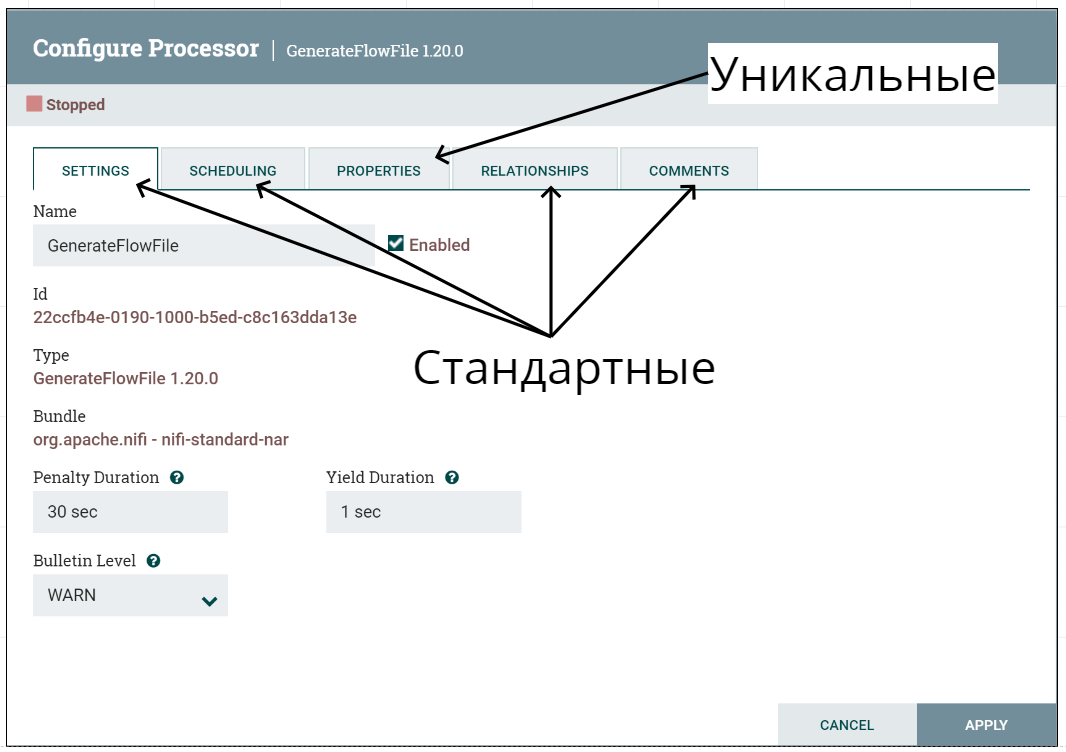
Каждый процессор содержит как стандартные для всех, так и уникальный список конфигурационных параметров для настройки под конкретную задачу.
- ConsumeKafkaRecord – создает FlowFile-ы, читая данные из топика Kafka
- GenerateFlowFile – создает указанное количество FlowFile-ов в заданную единицу времени с заданным контентом (полезен для тестирования)
- JoltTransformJSON – преобразует JSON в контенте по заданной JOLT спецификации
- MergeContent – объединяет контент нескольких FlowFile-ов в один FlowFile с общим контентом
- InvokeHTTP – вызывает HTTP API, передавая контент FlowFile-а в HTTP body
- RouteOnContent – маршрутизация FlowFile-ов в разные соединения-очереди по заданному условию
- ControlRate – используется для контроля скорости передачи FlowFile-ов вниз по течению (более гибкая настройка по сравнению с механизмом back pressure очереди)
Каждый процессор содержит как стандартные для всех, так и уникальный список конфигурационных параметров для настройки под конкретную задачу.
То, какого вида соединения могут исходить из процессора, определяется типом и настройками процессора. Многие процессоры содержат стандартные соединения “Success” и “Failure” для успешно и неуспешно обработанных FlowFile-ов соответственно, для некоторых процессоров (например RouteOnContent) пользователь сам может определять список соединений и логику, по которой туда попадают FlowFile-ы.
Соединенные процессоры и группы могут образовывать циклы (конечные или бесконечные):
Соединенные процессоры и группы могут образовывать циклы (конечные или бесконечные):
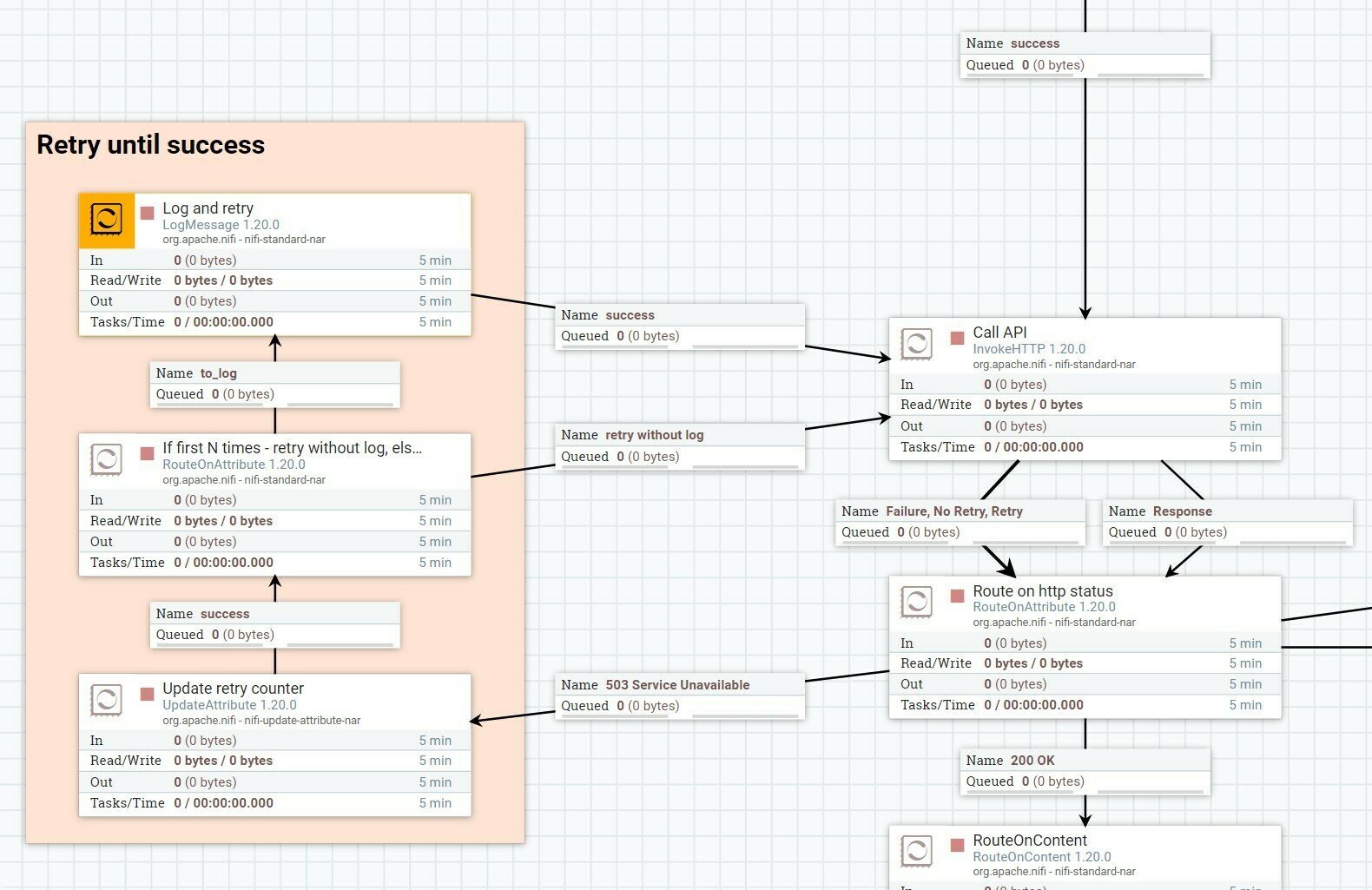
Для соединения в настройках процессора можно указать terminate-поведение. FlowFile-ы попадающие в такое соединение не передаются вниз по течению, а уничтожаются. Вам придется использовать такие terminate-соединения в конце обработки, т.к. Nifi считает некорректными процессоры, соединения которых не отмечены как terminate и не соеденены ни с каким компонентом ниже по течению [^].
Также у процессоров есть механизм retry – для любого соединения-очереди в настройках процессора можно указать retry-поведение, что означает что всякий FlowFile, попавший в такое соединение, будет отправлен в предыдущую (входную) очередь, из которой он появился в данном процессоре. В зависимости от настроек, такие FlowFile-ы будут обработаны повторно сразу или через некоторое штрафное время указанное количество раз, а затем, если их пункт назначения не поменяется на другое соединение, все таки попадут в нижеследующую очередь с retry-поведением (или будут уничтожены если соединение настроено на поведение terminate + retry) [^].
Философия Nifi [^] [^] не приветствует широко-функциональные процессоры, т.е. такие штуки как ExecuteScript – это скорее исключение из правил, и не смотря на то, что его задача – исполнять произвольный скрипт, вы все равно ограничены рамками определенного набора интерфейсов и абстракций.
Если ни один процессор вам не подходит, вам придется:
- Либо писать Java имплементацию своего процессора как отдельный NAR package (аналог JAR)
- Либо реализовывать свою логику где-то за пределами Nifi и далее как-то интегрировать ее с Nifi (через API / брокер сообщений и т.п.)
ControllerService
Контроллеры инкапсулируют в себе специализированную задачу или является интерфейсом стандартных настроек, которые не связаны с прямой обработкой FlowFile-ов [^]. Как и в случае с процессорами, Nifi содержит около сотни готовых контроллеров.
Типичные примеры контроллеров:
- DistributedMapCacheServer – предоставляет имплементацию key-value кэша на случай, если вам не хочется разворачивать что-то отдельное вроде Redis.
- StandardSSLContextService – хранит keystore и/или truststore настройки для SSL/TLS подключений
- DBCPConnectionPool – connection pool для подключения к БД (используется например процессором ExecuteSQL для запросов к БД)
Контроллеры подключаются как плагины к заранее определенным интерфейсам в процессорах, в других контроллерах, в задачах сбора отчетов (Reporting Tasks) [^] и в поставщиках настроек (Parameter Providers) [^]. В результате, с одной стороны, контроллеры можно использовать для устранения дублирования, настроив один экземпляр контроллера и переиспользуя его в нескольких компонентах, с другой стороны с помощью этого механизма можно варьировать конкретные этапы и конфигурационные параметры работы конкретного компонента, к которому он подключен.
Например, если Kafka топик содержит avro-схему сообщений, процессор-потребитель можно настроить так, чтобы в ходе получения данных из топика он обращался к контроллеру AvroReader (устанавливается в процессор через параметр Value Record Reader) с определением хранилища avro-схем (через подключенный к нему контроллер ConfluentSchemaRegistry) для конвертации данных из avro-представления в имплементацию Java интерфейса Record, а затем переводил Record в JSON (через контроллер JsonRecordSetWriter подключенный к процессору через параметр Record Value Writer). В результате процессор будет отдавать данные в JSON формате, а не в изначальном формате avro, в котором они хранятся в Kafka топике.
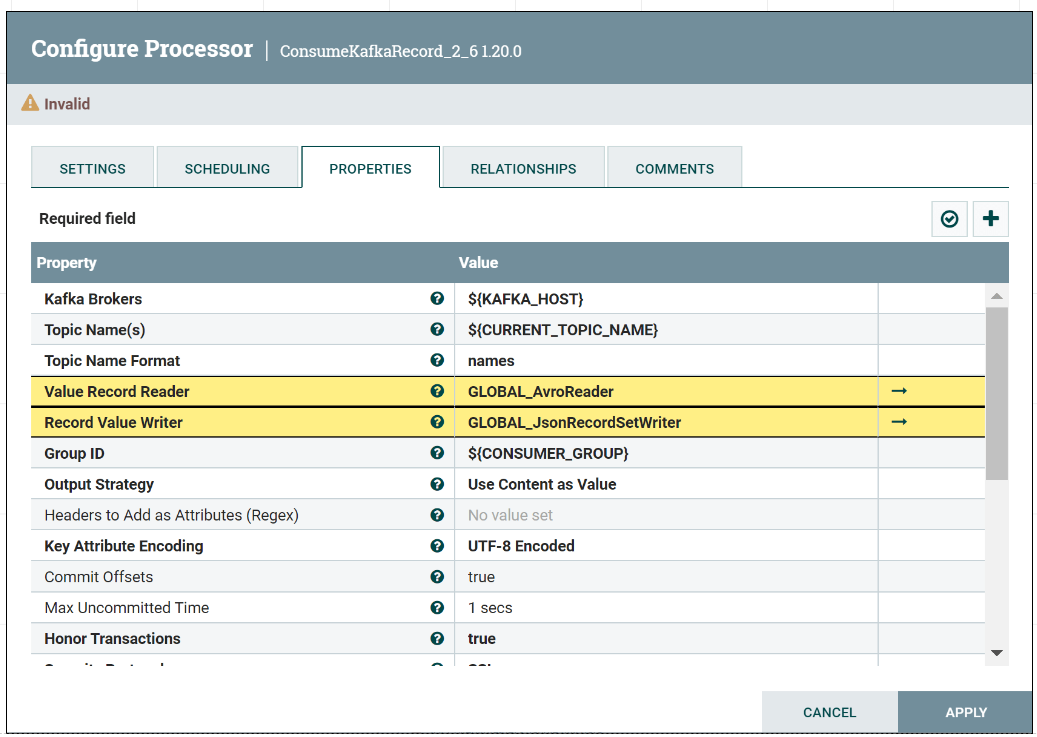
Контроллеры действуют в рамках JVM [^]. При этом результаты работы / состояние конкретного инстанса контроллера может использоваться совместно несколькими компонентами [^].
Контроллер может быть сконфигурирован в любых границах (уровнях / scope-ах) – например в корне или в конкретной группе процессоров. При этом процессор / контроллер имеет доступ ко всем контроллерам на пути по scope-ам от своей непосредственной группы до корня по иерархии вложенных групп (поэтому очень рекомендуется уникальное именование экземпляров контроллеров).
Если ни один готовый контроллер вам не подходит, вам придется писать Java имплементацию своего контроллера как отдельный NAR package [^] [^], см. также Кастомизация.
Process group
Позволяют объединить несколько процессоров в логические группы [^]
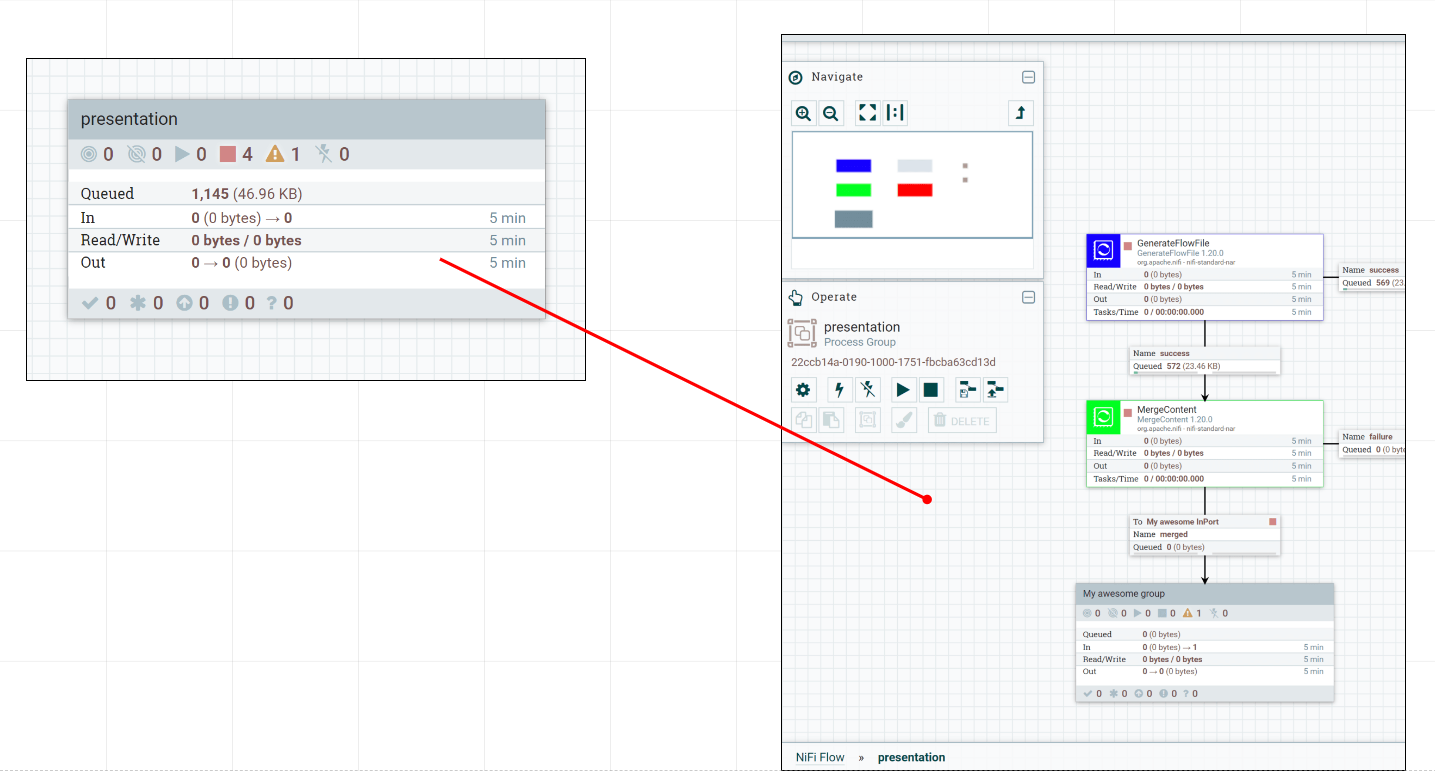
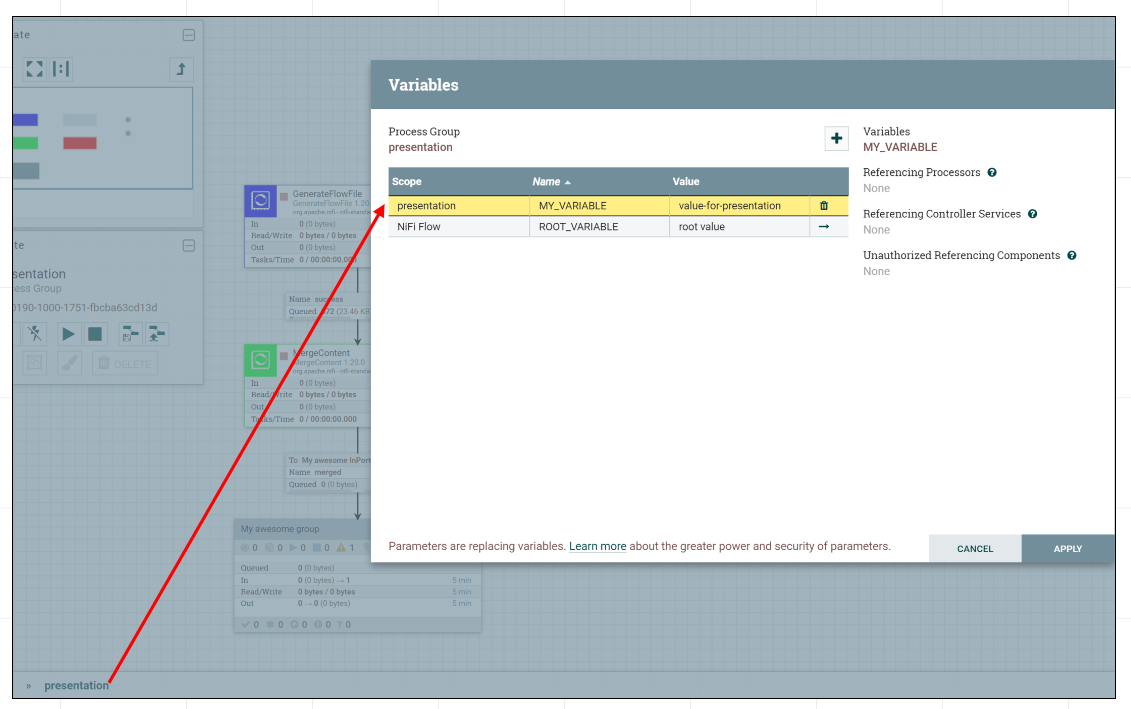
Также такие группы служат scope-ми для переменных или подключаемых контроллеров.
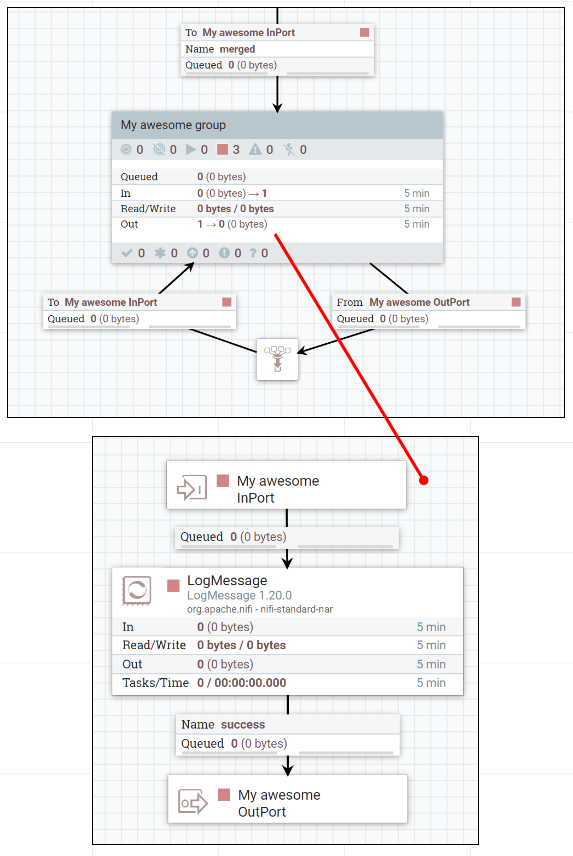
Группы могут соединяться с внешними процессорами и другими группами через порты с соединениями-очередями:
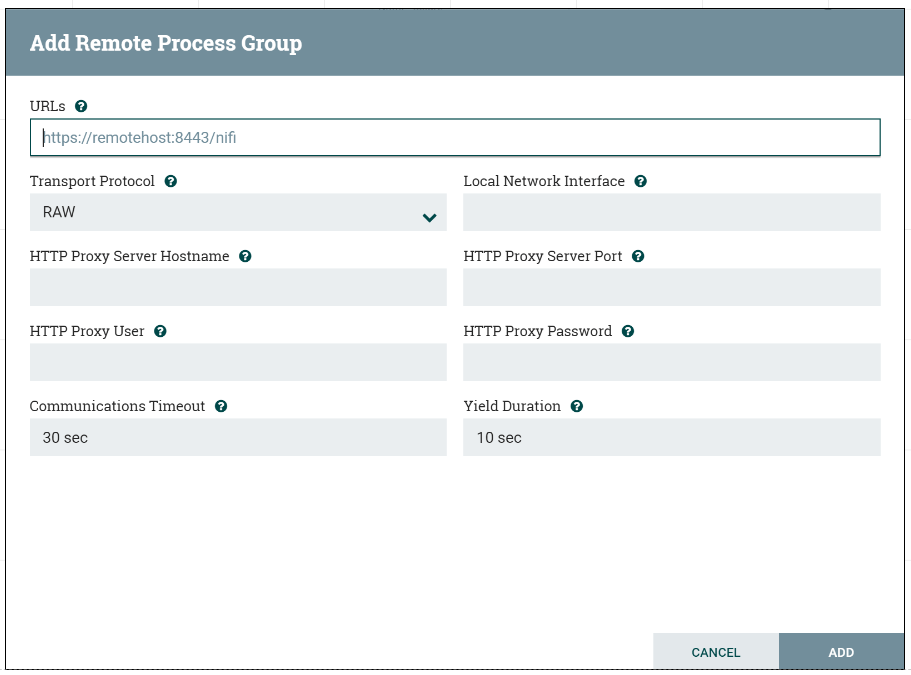
Есть также особый вид групп – Remote Process Group, которые используются как средство связи потоков данных между разными экземплярами Nifi не входящими в один кластер (предпочтительно через s2s protocol [^]). Такая возможность полезна в случаях, если например ваши потоки данных частично можно обрабатывать на небольших серверах уровня отдела с отдельными экземплярами Nifi, но также часть данных нужно отправлять в большой централизованный Nifi кластер уровня предприятия для общей обработки.
Во второй части расскажу про кастомизацию и поделюсь тем, что пригодилось мне при работе с NiFi в проектах. Объясню, какие гарантии дает NiFi и как оценивать нагрузку и подбирать ресурсы. Покажу, как быстро развернуть NiFi через Docker, зачем нужен Expression Language и чем отличается Minifi.





