За более 10 лет работы мы в CosySoft разработали множество сложных и высоконагруженных решений, например, электронный дневник или модули для управления огромным производством. Наши проекты разные, иногда даже уникальные, но у всех них есть одна общая черта. На всех без исключения проектах мы стараемся уделять много времени настройкам мониторинга, чтобы быть уверенными в разработке и эксплуатации продукта.
Кто наблюдает за наблюдателями
DevOps-инженеры играют ключевую роль в настройке мониторинга продукта. Как правило, они имеют большой опыт работы с различными инструментами и технологиями, что позволяет им выбрать наиболее подходящие инструменты для конкретных требований продукта и создать комплексную и надежную систему мониторинга.
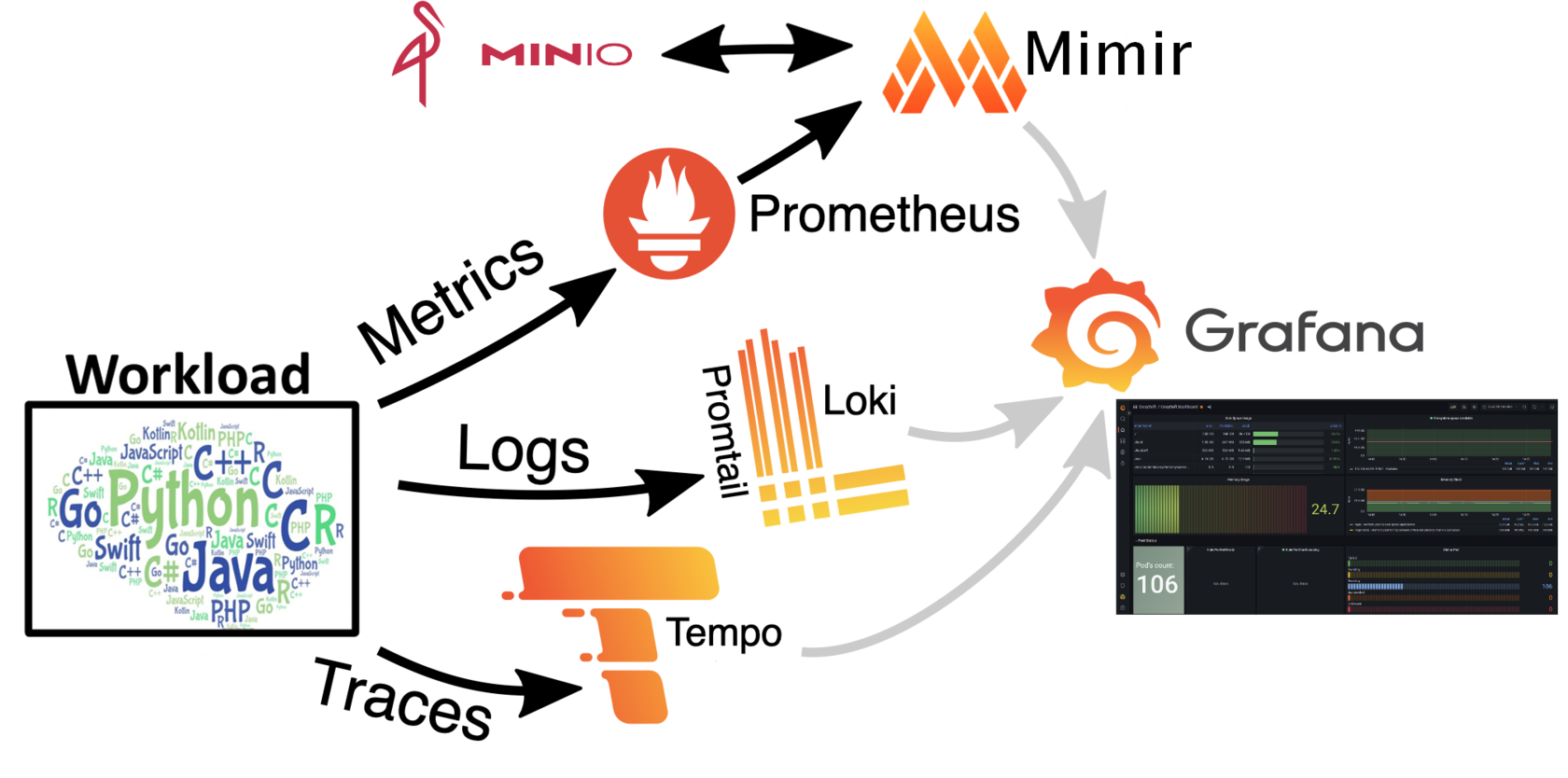
Пример использования стека
Такой observability stack мы реализовали для продукта крупной инвестиционной компании.
С помощью настроенной системы мы отслеживали транзакции, кредитование и множество других финансовых операций из наших приложений. Также мониторинг позволял увидеть сколько уникальных пользователей находится в системе, когда происходят пиковые нагрузки при торгах.
На основе собираемых логов аналитики инвестиционной компании прогнозировали рынок и следили за состояниями транзакций.
Метрики отправлялись клиенту в удобном виде (графики и простые фреймы логов) для дальнейшего масштабирования и отладки работы сервисов.
Сбор и передача логов
Журналы (логи) содержат записи о событиях, ошибках, предупреждениях и других важных сообщениях, которые происходят внутри продукта. Promtail собирает логи и отдает их в Loki.
Loki
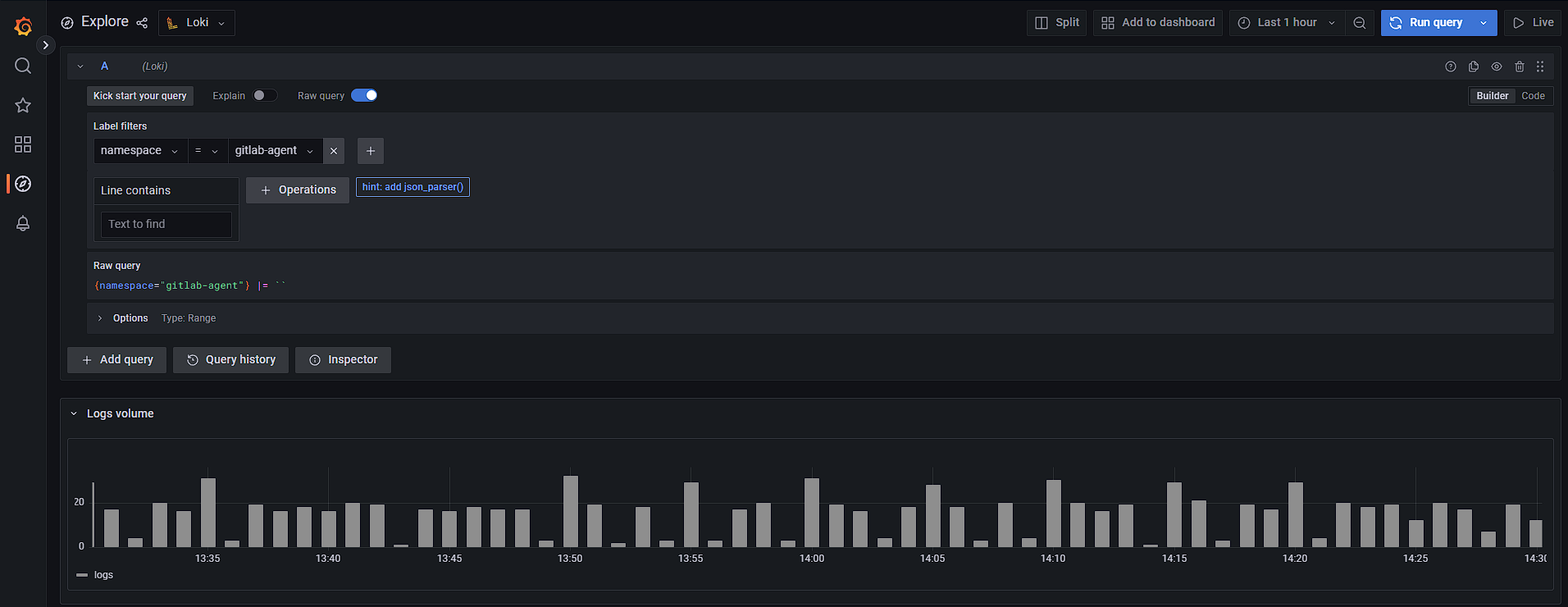
Горизонтально масштабируемая, многопользовательская система агрегации журналов, созданная на основе Prometheus. Экономичная и простая в эксплуатации.
Преимущества
- Возможность горизонтального масштабирования для обработки высокой нагрузки журналов.
- Оптимизированный подход к хранению журналов, который позволяет сжимать и фрагментировать данные.
- Плотная интеграция с экосистемой Prometheus обеспечивает единый интерфейс для наблюдаемости и отладки системы.
Promtail
Promtail отправляет содержимое локальных журналов в Loki или в облако Grafana Cloud. Обычно он развертывается на каждой машине, на которой установлены приложения, подлежащие мониторингу.
- Создан для эффективной обработки и отправки журналов, что снижает нагрузку на систему и позволяет работать в масштабируемых средах.
- Promtail легко интегрируется с другими компонентами системы Loki. Простой процесс настройки позволяет быстро настроить передачу журналов.
- Гибкая конфигурация, позволяющая настроить источники сбора журналов, фильтры, цели отправки и другие параметры.
Сбор метрик
Это данные о загрузке сервера, использовании памяти и процессора, пропускной способности сети, времени ответа и задержках запросов. Метрики производительности помогают определить эффективность и скорость работы продукта.
Prometheus
Гибкий и мощный механизм сбора метрик, который позволяет собирать данные из различных источников.
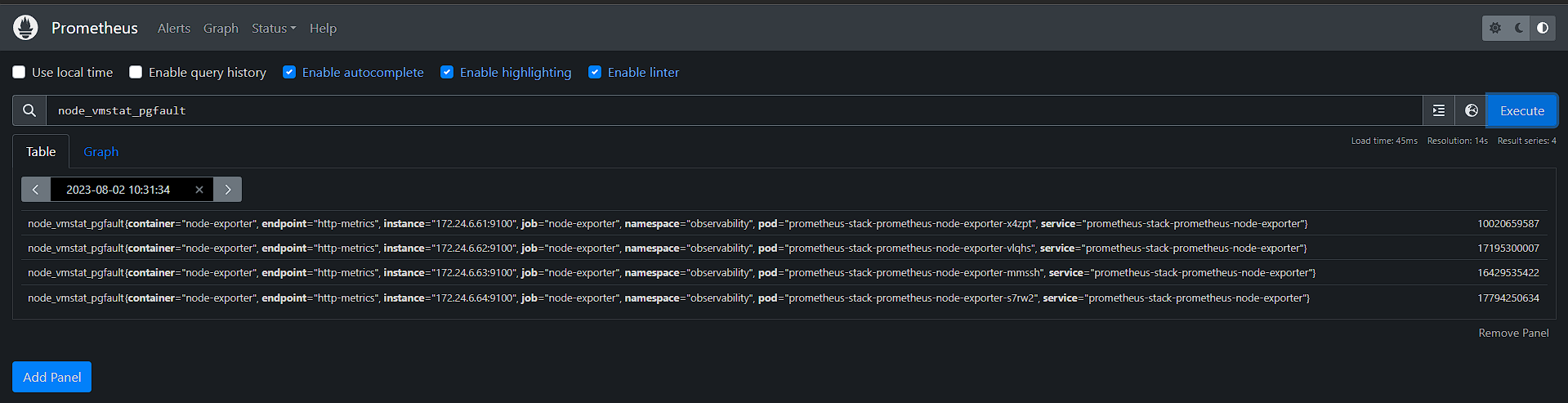
- Хорошо подходит для сбора и анализа данных, представленных в виде временных рядов (time series). Все метрики хранит в собственной БД.
- Поддерживает протоколы HTTP, SNMP, DNS, и позволяет пользовательские интеграции.
- С помощью PromQL (Prometheus Query Language) можно выполнять сложные запросы, фильтрацию, агрегацию и математические операции над метриками.
Визуализация
Центральный элемент стека — Grafana. Это платформа для визуализации и анализа данных, с помощью которой можно создавать гибкие дашборды и графики.
Победить современный стек Grafana не так уж и просто — нужно потратить много времени на изучение PQL-запросов, разобраться с написанием скрапов Prometheus, научиться писать маршруты для Promtail и Loki. Но результат будет великолепен.
Grafana
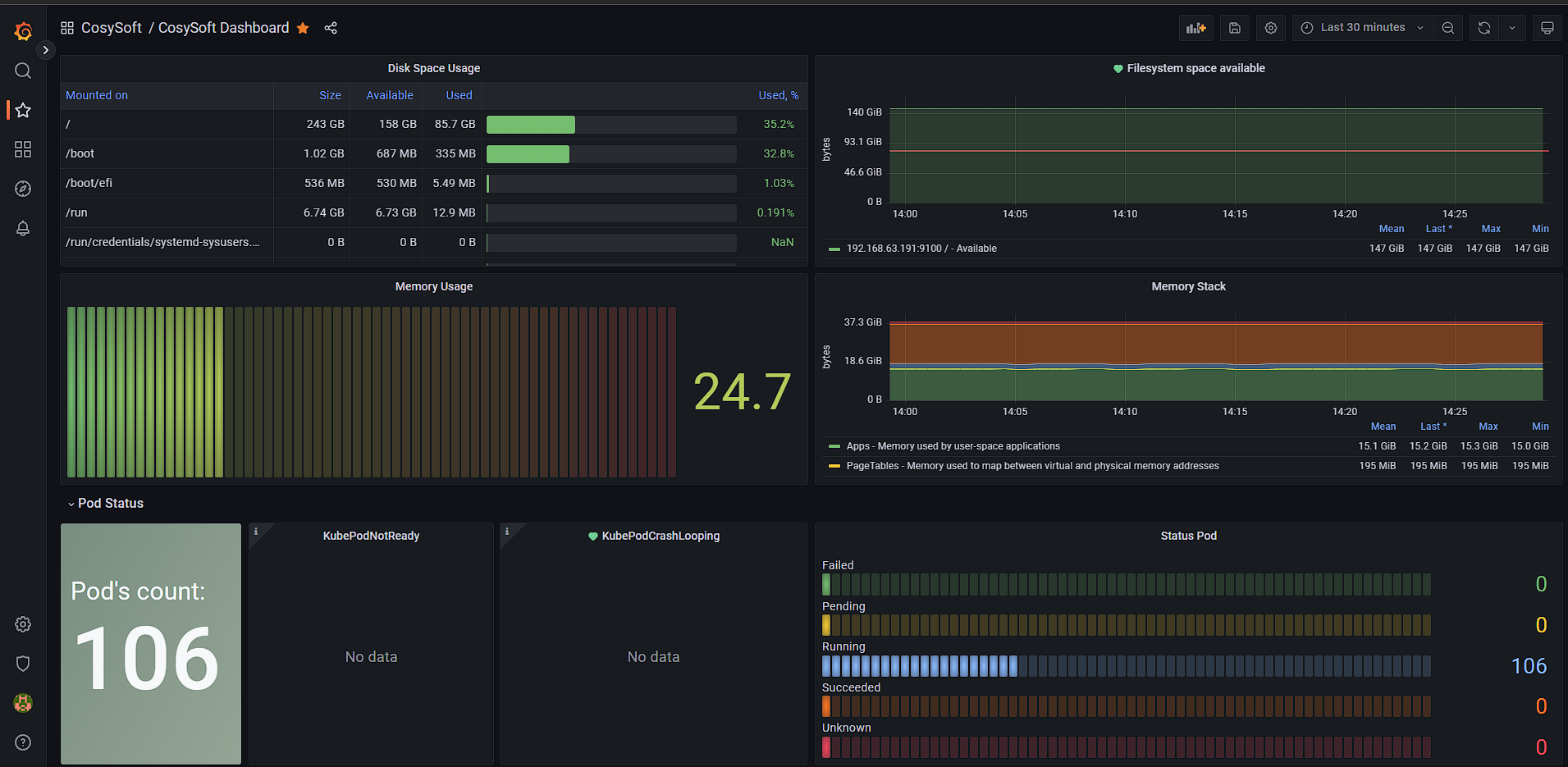
- Дает широкий спектр возможностей для создания настраиваемых и интерактивных визуализаций. Предлагает множество визуальных компонентов, графиков и панелей, а также возможность создания собственных шаблонов и дашбордов.
- Интегрируется с множеством различных источников данных, включая Prometheus, InfluxDB, Elasticsearch, MySQL и другие. Это позволяет получать данные из разных источников и объединять их в одном месте для создания всесторонних визуализаций.
- Интуитивно понятный и простой в использовании интерфейс, который делает процесс создания и настройки визуализаций легким и удобным.
Long-term хранилище с быстрым доступом
Если Prometheus используется для сбора и хранения метрик, то Grafana Mimir обеспечивает оптимизацию и долгое хранение этих данных.
Наличие Мимира как long-term хранилища позволяет получать больше полезных данных. На полученные логи и метрики применяются ETL- и ML-системы, которые анализируют эти данные, обучаются на них и делают прогнозы.
Grafana Mimir
Mimir позволяет оптимизировать доступ и анализ метрик в больших масштабах и ускоряет выполнение сложных запросов.
- Мощный индексирующий и поисковый движок, который обеспечивает эффективный поиск данных. Позволяет выполнять сложные запросы и фильтрацию данных в реальном времени.
- Разработан с учетом гибкости и расширяемости, что позволяет адаптировать его под различные потребности и сценарии использования.
- С помощью API и плагинов можно создавать собственные расширения, интегрировать сторонние инструменты и настраивать систему под свои потребности.
Менеджер оповещений
События и алерты уведомляют о нарушениях, превышениях заданных порогов или других критических событиях.
Alertmanager
Компонент позволяет настраивать и управлять правилами алертинга, обрабатывать и фильтровать оповещения и отправлять их на различные каналы связи.
- Позволяет определить правила и условия, при которых должны генерироваться оповещения. Это может быть основано на определенных пороговых значениях метрик или других условиях, которые могут указывать на проблемы.
- Может группировать оповещения, связанные с одной проблемой или событием, чтобы предотвратить спам и дублирование сообщений.
- Позволяет настроить отправку оповещений на различные каналы связи, такие как почта, Telegram, Slack, Rocket.Chat. и другие системы управления инцидентами.
Итоги
Стек Grafana & Prometheus универсален и очень удобен. Мы используем эти инструменты на многих проектах для отслеживания нагрузок на приложения и системы в момент разработки и вывода в продакшн. Стек одинаково хорошо подойдет и для высоконагруженных систем, и для маленьких приложений.
Фактический набор инструментов зависит от конкретного продукта, его требований и целей мониторинга.





