Привет, я Антон, backend-разработчик в CosySoft. В цикле статей я рассказываю про Apache NiFi — инструмент для работы с потоками данных, который мы используем в проекте.
Это продолжение моего гайда про NiFi. Если вы не читали первую часть — там базовая теория: что такое NiFi, зачем он нужен, как устроен и что из себя представляет как инструмент. Во второй части переходим к вещам, которые полезно знать при работе с NiFi в реальных проектах. Разберем:
— кастомизацию
— как NiFi хранит данные и что такое FlowFile
— как оценивать нагрузку и подбирать ресурсы
— какие гарантии дает по доставке данных
— как быстро поднять NiFi локально через Docker Compose
— зачем нужен NiFi Expression Language
— и чем отличается от Minifi
Кастомизация Apache NiFi: с чего начать
Расширение Nifi не простая тема, можно начать с этих ресурсов.
Кастомизация Nifi требует:
- Глубокого понимания внутреннего устройства Nifi (кажущаяся простота в UI может создать впечатление что вы быстро погрузитесь в тему расширения Nifi достаточно просто, это впечатление обманчиво)
- Глубокого понимания Java concurrency [^] (предполагается, что почти любая работа может производиться параллельно даже в standalone-режиме)
- Хорошего понимания концепции Java ClassLoader, т.к. она играет важную роль в бесконфликтном управлении расширениями Nifi [^] [^] [^]
Основные сущности, поддающиеся расширению [^]:
- Processors (процессоры)
- ControllerService (контроллеры)
- ReportingTask (интерфейс публикации метрик и мониторинга Nifi во внешние системы – в логи, в email, в web-сервисы и т.д.)
- ParameterProvider (интерфейс управления конфигурационными параметрами извне)
- FlowFilePrioritizer (алгоритм приоритизации FlowFile-ов в соединениях-очередях)
- AuthorityProvider (авторизация пользователя)
Также доступна ограниченная кастомизация UI процессоров и UI просмотра контента FlowFile-ов [^].
Факты о Nifi, которые вам следует знать
Этот раздел дополняет остальные, здесь вы найдете разнообразные примечательные вещи о Nifi которые мне показались важными.
Особенности хранения данных FlowFile
Как уже было сказано в разделе Архитектура, атрибуты хранятся в FlowFile Repository, контент – в Content Repository.
При этом контент и атрибуты FlowFile это immutable записи на диске, FlowFile держит ссылку на них [^]. При "изменении" контент / атрибут копируется с изменением (copy-on-write) в новую область диска [^], ссылка на них меняется [^]:
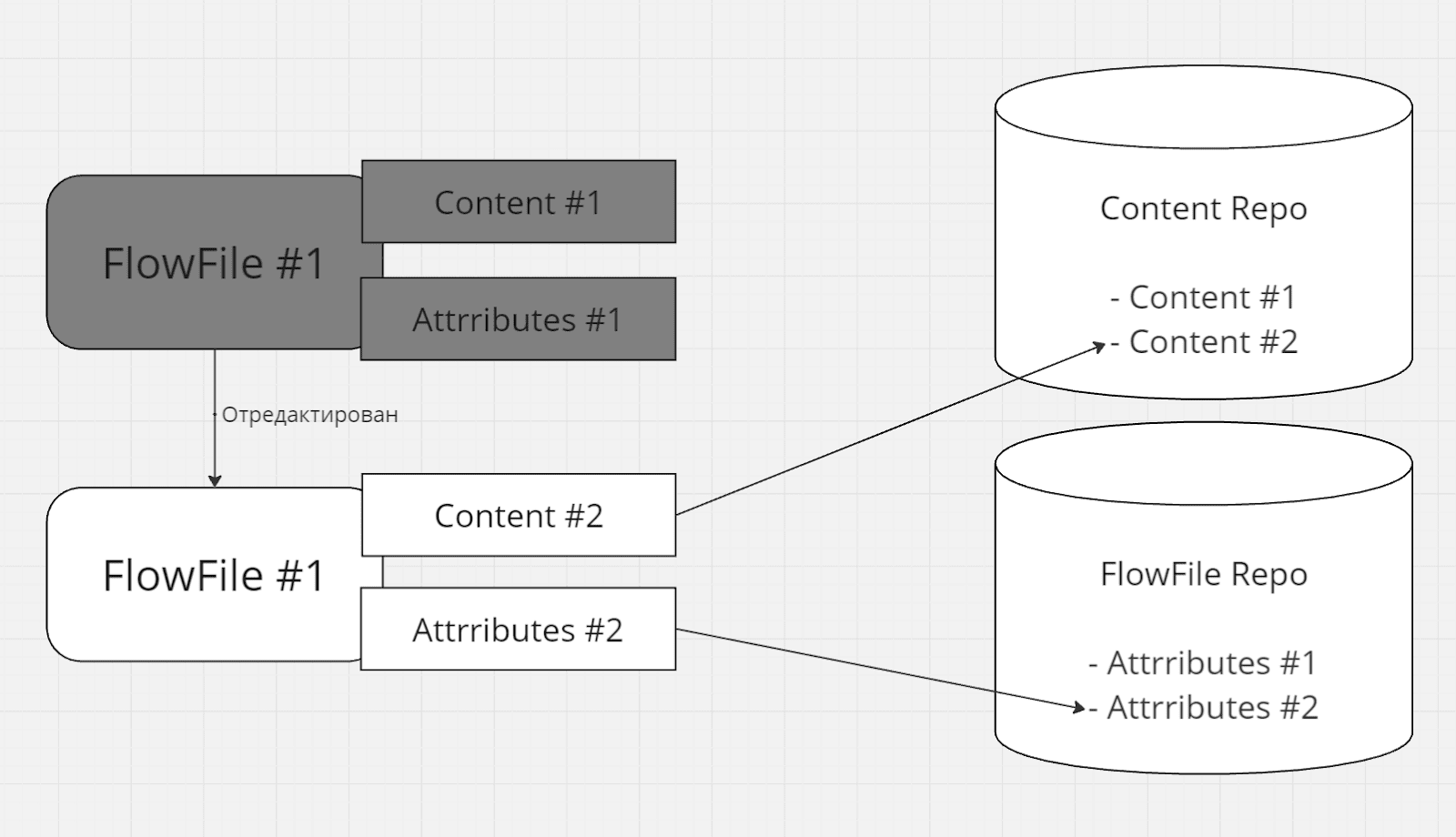
Immutable запись и copy-on-write имеет ряд преимуществ:
- Более быстрая работа с диском, кеширование на уровне ОС [^], thread-safety [^], и прочее
- Старая копия контента очищается не сразу, и только если нет других FlowFile-ов с ссылкой на эту версию контента (чем то похоже на Java GC) [^] [^]. В частности это позволяет заглядывать в историю и даже прогонять обработку заново, пока контент доступен [^]
- Если существует несколько копий FlowFile-а, контент не копируется, каждый получает ссылку на один и тот же контент:
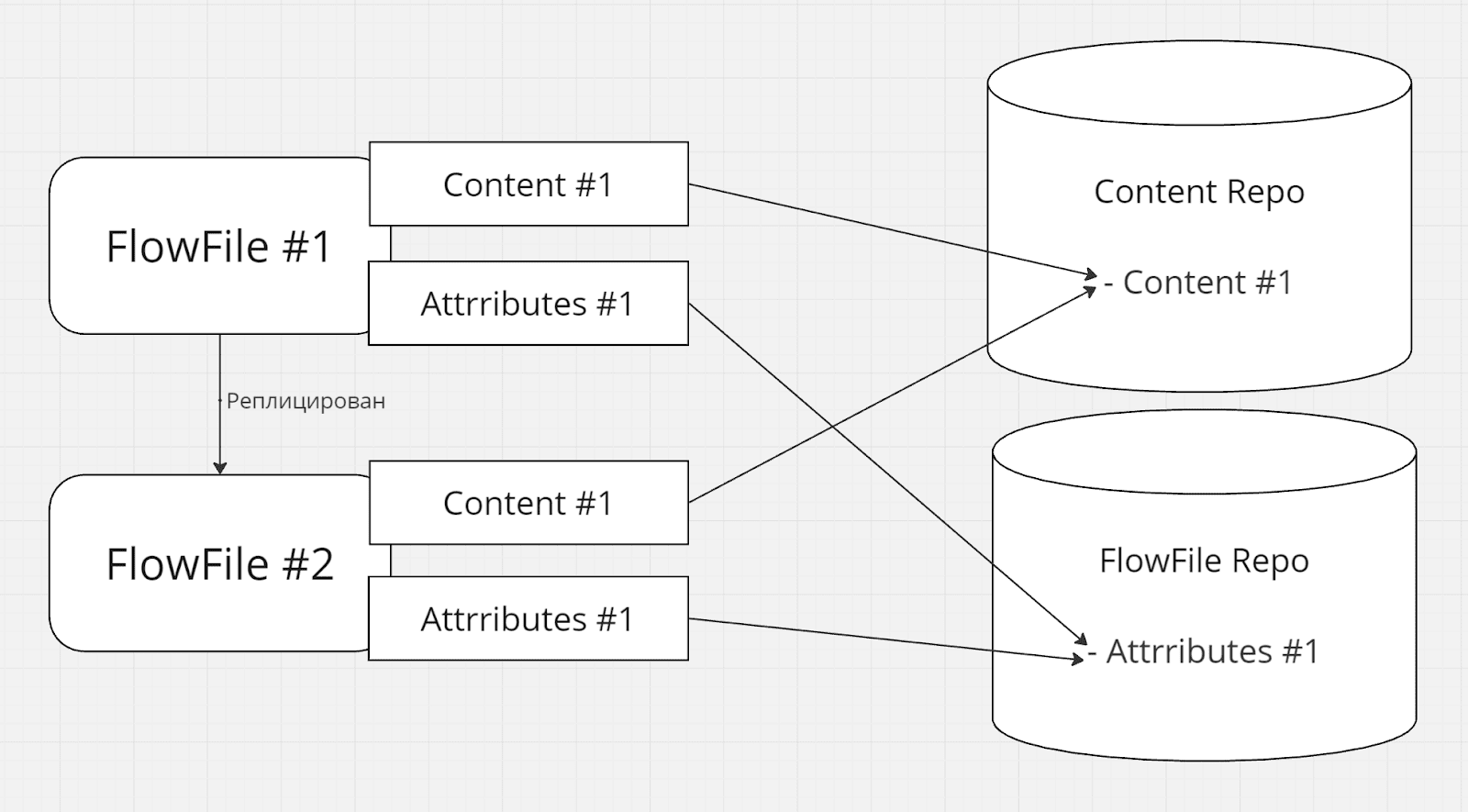
Далее каждая копия получает возможность изменить контент своим способом, получив собственную независимую новую версию контента, не влияя на контент других копий [^]:
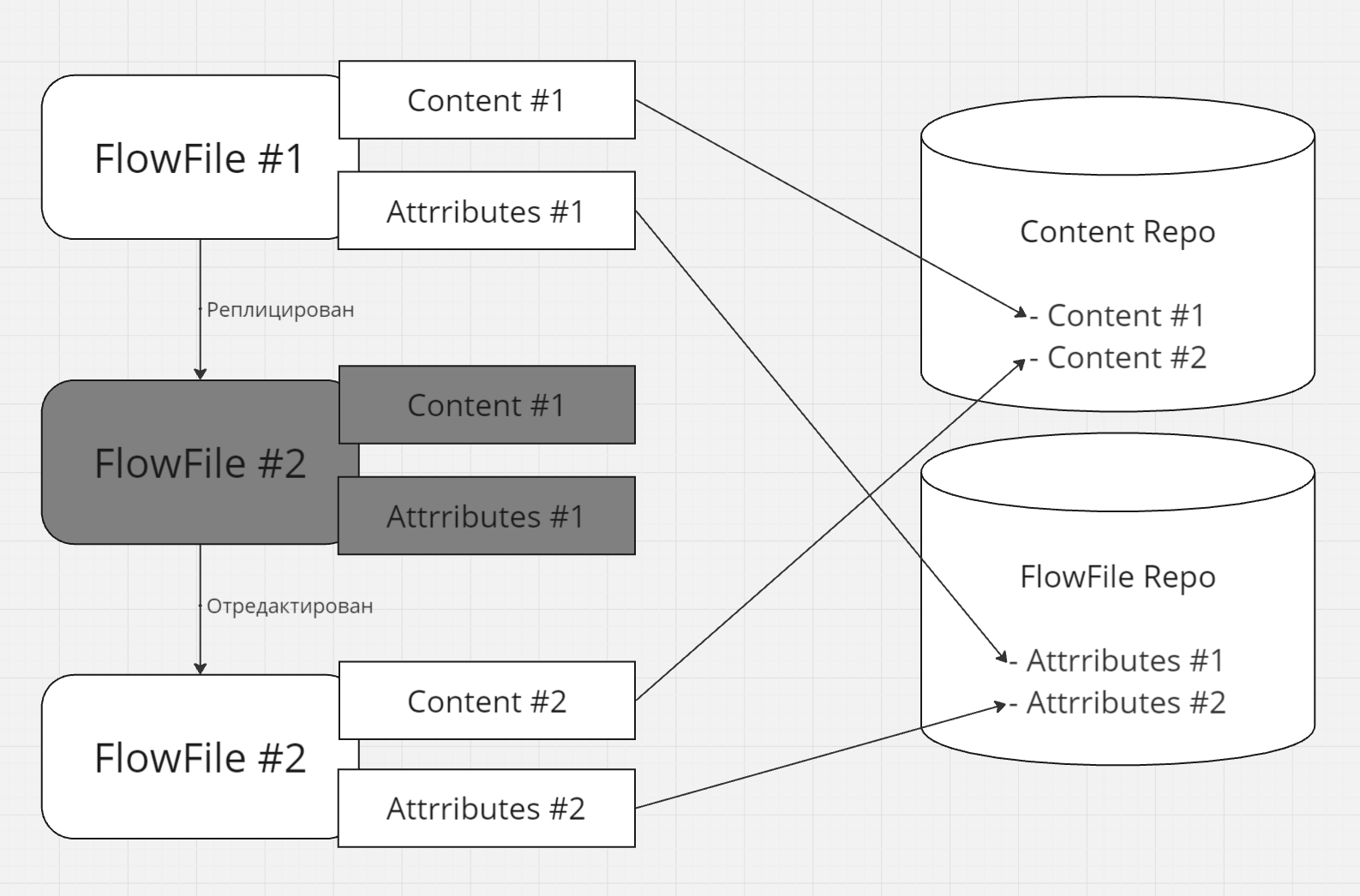
По умолчанию контент активных FlowFile-ов загружается в RAM (heap) только по необходимости (и то, не обязательно весь [^]), а key-value атрибуты активных FlowFile-ов находятся полностью в памяти (поэтому размер каждого значения может быть ограничен) [^].
Важные выводы из вышесказанного: вы сильно выиграете в производительности, если сможете выполнить работу используя только key-value атрибуты, по минимуму обращаясь к контенту [^].
Выдерживаемые нагрузки и сайзинг
Nifi играет заметную роль в big-data стеках [^] [^] [^] и при правильной настройке и достаточных hardware-ресурсах он может обрабатывать довольно большие объемы данных [^]. В standalone-режиме на Nifi можно достичь обработки нескольких сотен мегабайт в секунду [^], в режиме кластера речь уже может идти о десятках гигабайт в секунду [^] [^] [^].
Конечно, многое также зависит от сложности обработки данных. Nifi на разумных hardware мощностях хорошо подходит под обработку малых и средних объемов данных, выдерживая при этом достаточно интенсивную модификацию контента. Но сложная обработка очень больших объемов данных в Nifi потребует существенных hardware ресурсов. Nifi лучше проявляет себя при обработке данных в streaming-режиме, использующих относительно легковесные операции.
Для типичных нагрузок, достижимых настройками по-умолчанию и стандартными hardware-ресурсами в официальной документации и статьях Cloudera рекомендуют закладываться на следующие величины:
- 50-100 Мб/сек I/O для стандартных дисков / RAID [^] или больше. Отдавайте предпочтение SSD [^]. При больших объемах данных рекомендуется выделять отдельные диски для каждого Content Repository и каждого Provenance Repository – если в вашем кластере много нод и каждая интенсивно работает с одним и тем же физическим диском, то I/O операции могут стать узким местом. Необходимый объем дисков зависит от объема ваших данных, а также от того, как долго вы хотите хранить вышедший из употребления контент и provenance-историю.
- CPU должны поддерживать несколько десятков программных потоков для заметных объемов обрабатываемых данных [^]. В справке Cloudera рекомендуют минимум 4 ядра на ноду, лучше – 8 ядер [^] или больше. Такие операции как шифрование или сжатие данных могут потребовать повышенных затрат CPU.
- Что касается оперативной памяти – ее должно быть достаточно не только для операций Nifi, но и для поддержания процессов JVM, прежде всего сборщика мусора [^]. Чем больше индивидуальных FlowFile-ов обрабатывается нодой в единицу времени, тем чаще потребуется сборка мусора. При настройке GC следует стремиться к снижению времени stop-the-world, особенно это важно в режиме кластера, т.к. GC паузы задерживают heartbeat-сигналы, что может привести к отключению такой ноды от кластера [^]. Также, рекомендуется принять во внимание доступность оперативной памяти для кэша ОС, что позволяет сократить операции чтения с диска [^]. В зависимости от нагрузок рекомендуется начинать с 8 - 32 ГБ на каждую ноду, из них несколько (2 - 8 Гб [^]) на JVM с Nifi, остальное на ОС [^] [^], далее контролировать стабильность работы и по необходимости вносить изменения.
В дополнение к уже имеющимся ссылкам рекомендую также статью с roadmap масштабирования Nifi кластера.
Примите также во внимание, что правильная конфигурация самих процессоров Nifi может играть гораздо более существенную роль в пропускной способности ваших потоков чем вертикальное (наращивание hardware-ресурсов) или горизонтальное (добавление дополнительных нод) масштабирование – ознакомьтесь с этим плейлистом youtube где разбираются типичные ошибки, которых следует избегать.
Гарантии доставки
Гарантии доставки в Nifi напрямую зависят от того, о каком аспекте обработки данных в Nifi мы говорим, а также от того, как эта обработка настроена.
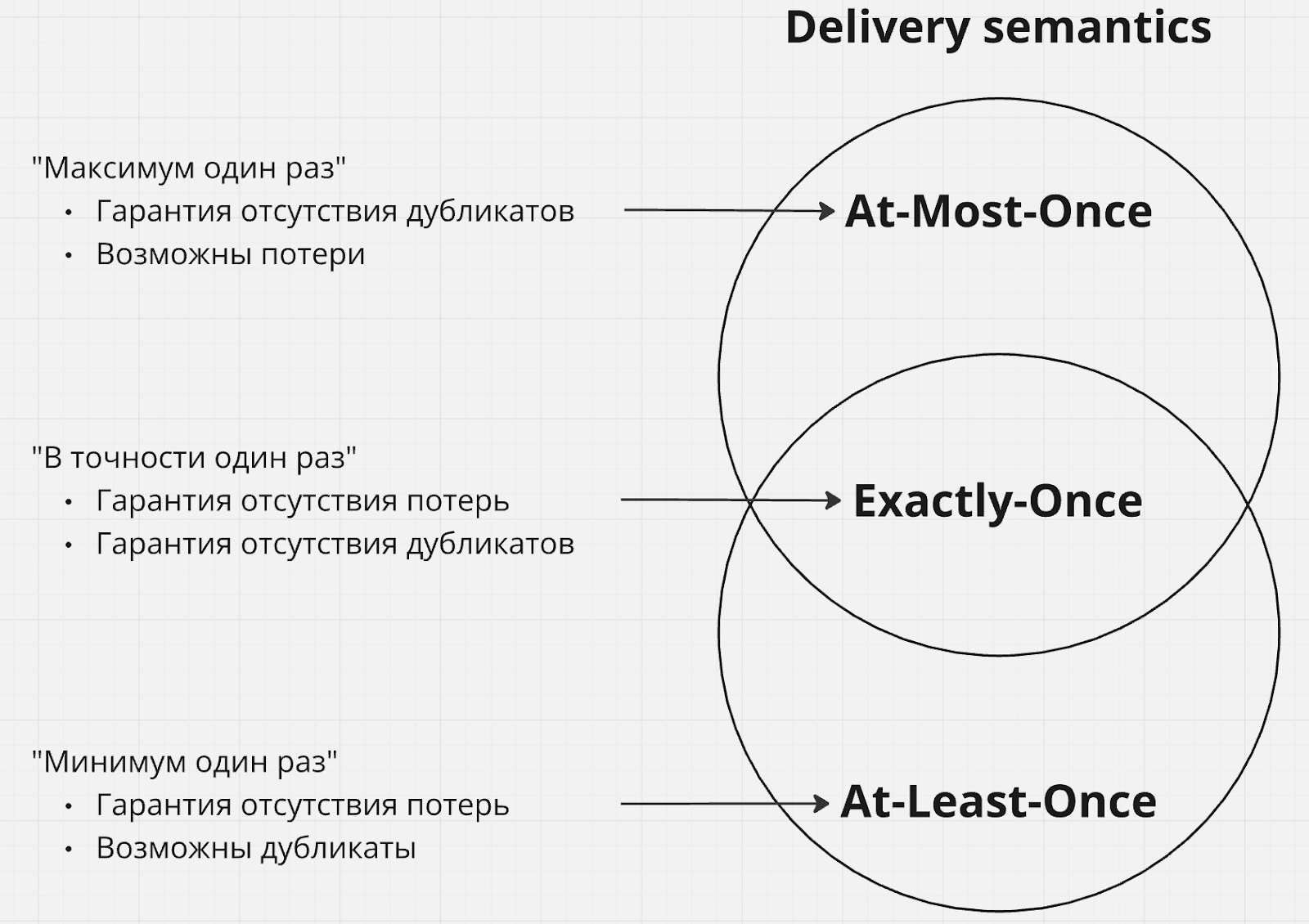
На этапе потребления данных из внешнего источника в Nifi, а также на этапе отправки данных из Nifi к внешнему потребителю – гарантия доставки зависит от реализации процессора и протокола внешнего источника / потребителя, в частности может гарантироваться at least once доставка при условии работы с протоколом, поддерживающем двухфазные коммиты (и при условии, что процессор их использует) [^].
Если речь идет об обмене данными между экземплярами Nifi через site-to-site протокол – опять же, здесь гарантируется at least once доставка за счет встроенной поддержки двухфазных коммитов [^].
Если данные уже находятся в Nifi (т.е. создан FlowFile, контент сохранен в Content Repository) и мы говорим про гарантии передачи FlowFile-ов между процессорами – здесь Nifi может гарантировать at least once доставку благодаря использованию WAL (который надо включить, т.к. по умолчанию он выключен) [^] [^] и транзакционной модели фиксации изменений (commit / rollback) в процессорах [^] [^] [^] [^]. В данном случае речь идет не о транзакциях реляционных БД, а о механизме коммита или отката специальной абстракции NiFi сессии – ProcessSession [^] через специальный java-callback. При этом каждый процессор управляет своей отдельной сессией независимо от других процессоров [^].
Если речь идет об обмене данными между экземплярами Nifi через site-to-site протокол – опять же, здесь гарантируется at least once доставка за счет встроенной поддержки двухфазных коммитов [^].
Если данные уже находятся в Nifi (т.е. создан FlowFile, контент сохранен в Content Repository) и мы говорим про гарантии передачи FlowFile-ов между процессорами – здесь Nifi может гарантировать at least once доставку благодаря использованию WAL (который надо включить, т.к. по умолчанию он выключен) [^] [^] и транзакционной модели фиксации изменений (commit / rollback) в процессорах [^] [^] [^] [^]. В данном случае речь идет не о транзакциях реляционных БД, а о механизме коммита или отката специальной абстракции NiFi сессии – ProcessSession [^] через специальный java-callback. При этом каждый процессор управляет своей отдельной сессией независимо от других процессоров [^].
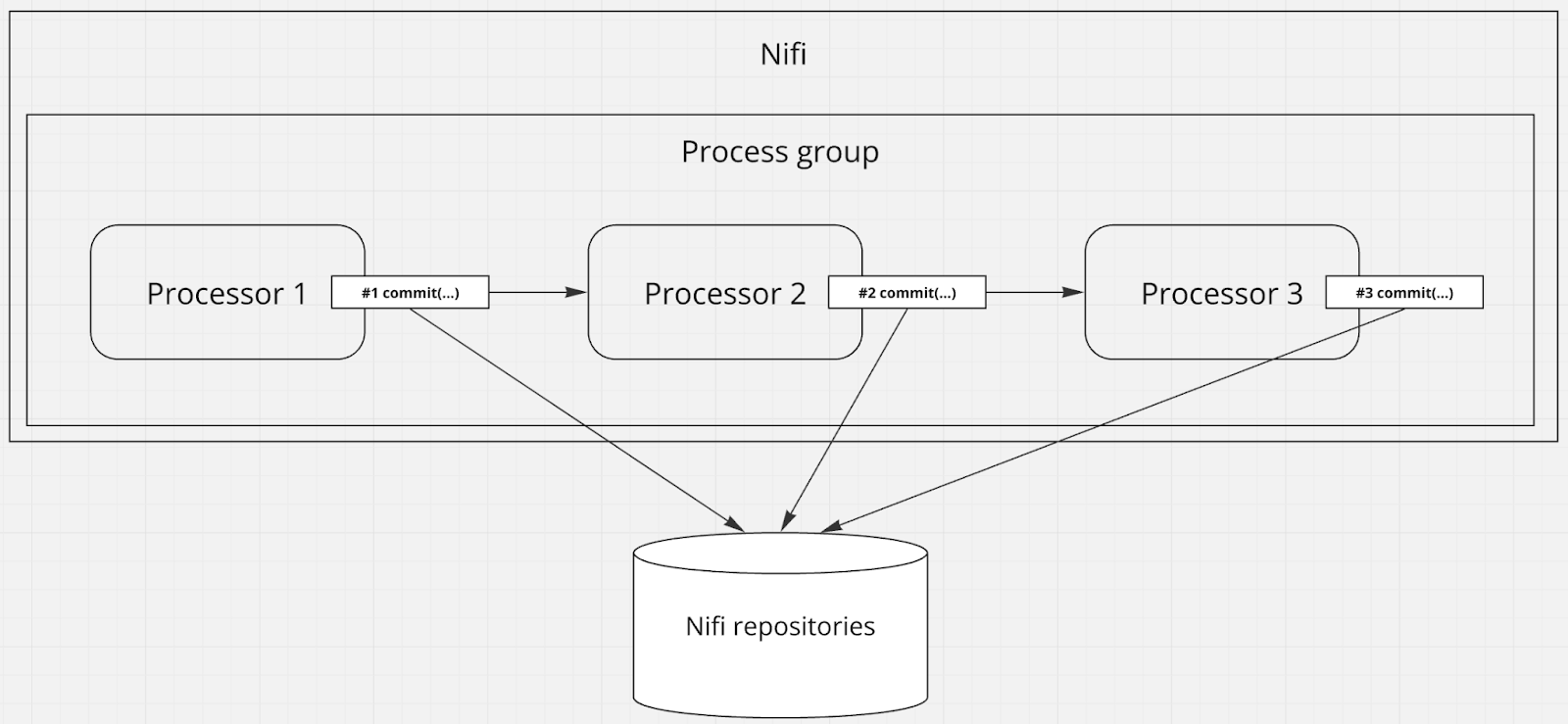
Помимо этого, за счет того, что контент FlowFile-ов вышедший из употребления не удаляется сразу же (по-умолчанию) [^] и существует история provenance-событий FlowFile-ов, возможен повторный перезапуск обработки FlowFile-ов [^] [^].
Stateless NiFi
В некоторых сторонних статьях и обзорах для Nifi сходу заявляется exactly once semantics, что долгое время было неверно, читайте хорошую email-переписку об этом в контексте взаимодействия с Kafka. Проблема как раз была в том, что exactly once недостижим без синхронизации коммита / отката сессий Nifi нескольких процессоров. Для того, чтобы решить эту проблему и дать возможность исполнять несколько процессоров в единой “транзакции”, в Nifi появился “Stateless NiFi Runtime Engine” [^] [^] [^] [^].
В IT сообществах периодически циркулируют дискуссии о принципиальной возможности или невозможности достижения exactly once semantics в любых распределенных системах [^] [^] [^], которые иногда заканчивается выводом о возможности достижения лишь “effectively-once delivery” через at least once delivery в связке с идемпотентным паттерном обработки данных [^]. В рамках этой статьи я не хочу спорить о терминах, погружаться в этот спор и примерять его на Nifi, ограничусь лишь тем, что вывод об effectively-once delivery кажется мне разумным подходом к разработке для предупреждения многих проблем.
Stateless NiFi работает так: вы выносите часть потока, который хотите выполнять в единой “транзакции”, в отдельную группу, которую затем можно запустить через процессор ExecuteStateless. Пока FlowFile-ы обрабатываются внутри такой группы, изменение их данных перестает сохраняться обычным способом в FlowFile Repository, Content Repository и Provenance Repository, вместо этого их изменения накапливаются как временно существующие дельты в java-heap или на диске [^] (отсюда название “Stateless”), а commit-callback-и сессий вызываются только после того, как FlowFile-ы успешно пройдут все этапы обработки внутри группы [^]. Если в какой то момент обработка FlowFile-а прервется из-за аварии, ни один commit-callback из ранее исполненных процессоров не выполнится, дельта пропадет после рестарта, а Nifi начнет повторную попытку обработки с самого начала.
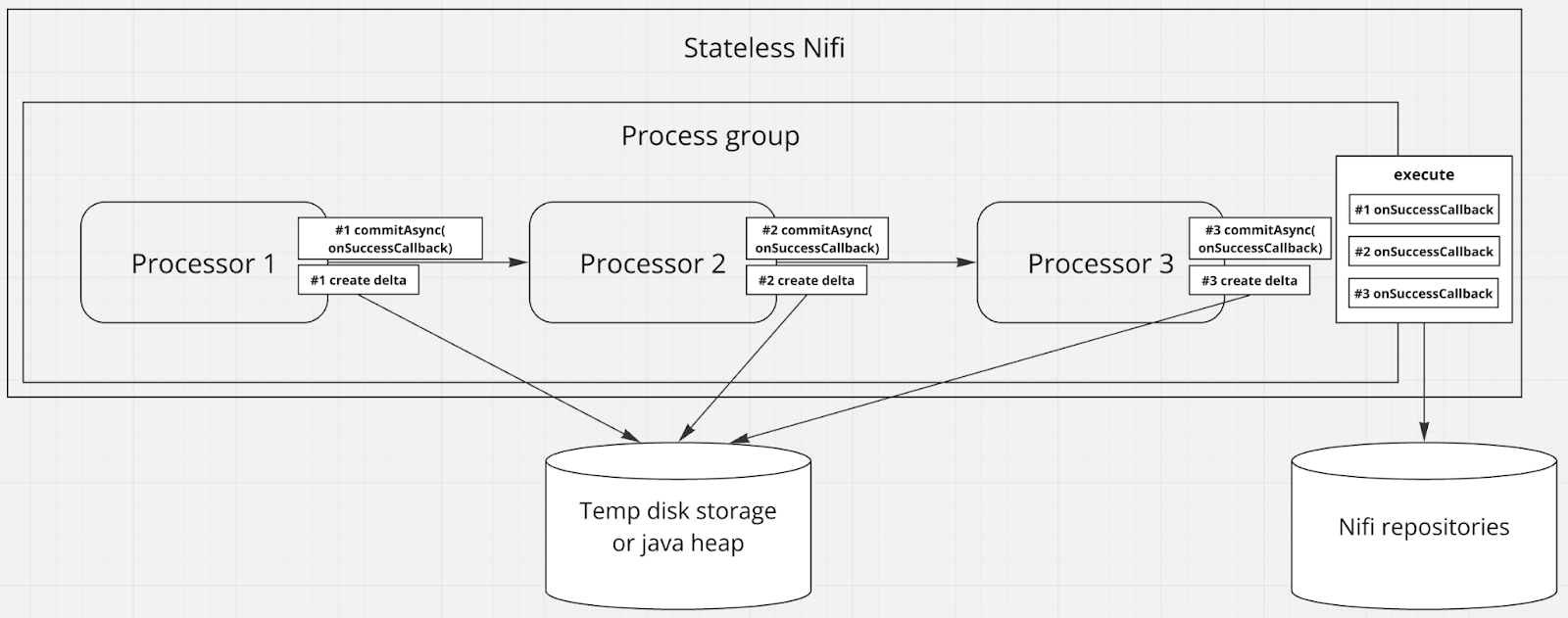
В результате можно достичь exactly once semantics (или effectively-once, называйте как хотите) для некоторых сценариев, например для Kafka [^].
Так как в результате аварий Stateless NiFi не сохраняет данные, важно чтобы источник мог повторно предоставить данные для новой попытки [^]. При side-эффектах в stateless-группе (например, HTTP POST) вы получаете at least once и должны предусмотреть дедупликацию или идемпотентность.
Заметьте, что поведение Stateless NiFi не всегда полностью соответствует традиционной Nifi обработке [^] [^] [^], что может потребовать смены подходов к дизайну ваших потоков [^] [^] [^] для этого режима работы.
Помимо запуска Stateless NiFi через ExecuteStateless процессор в обычном Nifi, его также можно запускать в виде отдельного Java-агента и даже добавлять в свои собственные Java-приложения в качестве библиотеки [^]. Описание потока и настройки при этом предоставляются через конфигурационные файлы.
Возможность поделиться наработками
В Nifi предусмотрена шаблонизация ваших решений в рамках кластера. Это значит, что произвольный набор процессоров, групп процессоров и соединений между ними можно превратить в шаблон, доступный вам и другим пользователям для переиспользования [^] [^].
Также, доступна выгрузка (download flow definition) группы процессоров в JSON формат, который затем можно превратить обратно в группу [^].
Если же вам нужен аналог системы контроля версий ваших настроенных потоков данных – Nifi предоставляет специальный инструмент NiFi flow registry, см. также руководство.
Безопасность
Nifi самостоятельно закрывает многие вопросы безопасности данных, предоставляя следующие возможности из коробки:
Шифрование при обмене, шифрование контента FlowFile-ов и чувствительных настроек (поля с паролями и т.п.). Nifi использует BouncyCastle, JCraft Inc. и встроенные библиотеки криптографии Java для TLS/SSL, SSH и шифрования чувствительных настроек [^].
Ведение логов действий пользователя и истории преобразования данных (provenance-события)
- Также, Nifi можно интегрировать с различными внешними хранилищами секретов (HashiCorp [^], AWS [^] [^], Azure [^] [^], Google [^])
- по логину/паролю (LDAP [^], Kerberos KDC [^])
- через single sign-on системы – OpenId Connect [^], SAML [^], Apache Knox [^] (поддержка Knox прекращена с major версии 2)
- с помощью клиентских сертификатов HTTPS если никакая другая стратегия аутентификации не действует [^]
Ведение логов действий пользователя и истории преобразования данных (provenance-события)
Подробную информацию по настройке можно найти в NiFi System Administrator’s Guide и Apache NiFi Walkthroughs.
Что касается политики раскрытия информации об уязвимостях, всю информацию можно найти здесь и здесь.
Интерфейсы для клиентов
У Nifi есть REST API [^] [^] и CLI [^] в основном для получения различной информации о текущем состоянии обработки данных и настроек, а также изменения настроек уже созданных потоков данных. В результате вы можете создавать клиентские программы, манипулирующие настройками или получающие информацию о текущих процессах Nifi.
Пример локального развертывания Nifi через Docker Compose
Nifi без проблем можно развернуть на локальной машине для разработки, тестов, экспериментов или личных нужд. Заметьте, что здесь мы не рассматриваем production-ready конфигурацию.
Развертывание Nifi версий 1.x.y
Я использовал Docker Compose на Windows, вот пример docker-compose.yml для простой standalone конфигурации без HTTPS.
Примонтированные директории появятся в директории nifi, которая в свою очередь появится в той же директории, в которой создан docker-compose.yml. Если вас это не устраивает, вы можете указать другие пути монтирования.
Если не хотите, чтобы контейнер с Nifi перезапускался автоматически (что обычно также означает автоматический запуск после включения / перезагрузки ПК если Docker Engine запускается после старта ОС) – замените restart: unless-stopped на restart: "no".
Обратите внимание, что в Docker образах (image) Nifi открыты порты 10000, 8443, 8080, 8000: EXPOSE map[10000/tcp:{} 8000/tcp:{} 8080/tcp:{} 8443/tcp:{}] [^]
- Порт 10000 (nifi.remote.input.socket.port) используется для Site-to-Site соединения, поэтому если собираетесь использовать Remote Process Group с RAW Transport Protocol – добавьте его в docker-compose.yml, например “- 10000:10000/tcp”
- Порт 8443 (nifi.web.https.port) используется для доступа к UI через HTTPS. В данном примере вместо него используется порт 8080 (HTTP). Обратите внимание – Nifi не поддерживает одновременную работу с HTTP и HTTPS [^]
- Порт 8080 (nifi.web.http.port) пробрасываемый на хост-порт 8087 (можете выбрать любой другой свободный порт на хостовой ОС) – для доступа к UI через HTTP.
- Порт 8000 – не связан с Nifi, этот порт открыт на случай необходимости дебага Nifi как Java приложения, см. закомментированную настройку java.arg.debug в /opt/nifi/nifi-current/conf/bootstrap.conf в контейнере.
Docker-образы подгружаются из стандартного docker-registry
Для запуска в фоновом режиме воспользуйтесь командой docker-compose -f docker-compose.yml up -d находясь в директории с файлом docker-compose.yml
После успешного запуска UI будет доступен на http://localhost:8087/nifi/ (если вы не меняли хост-порт для nifi.web.http.port)
Смотрите также более подробный гайд запуска через Docker без Docker Compose – Setting Apache Nifi on Docker Containers
Развертывание Nifi версий 2.x.y
Эти версии требуют немного другой конфигурации docker-compose.yml
Nifi будет доступен на https://localhost:8087/nifi/ (обратите внимание, здесь используется HTTPS в отличие от конфигурации версий 1.x.y) и потребует аутентификации.
Если не хотите погружаться в настройку пользовательской аутентификации, придется использовать одноразовые пары логина и пароля, которые генерируются при старте контейнера, получить их можно выполнив в терминале контейнера команду grep Generated logs/nifi-app*log (терминал контейнера вызывается через docker exec -it <идентификатор контейнера> /bin/sh).
Если вариант с одноразовыми реквизитами аутентификации слишком уныл для вас – зайдите в терминал контейнера, переключитесь в директорию /opt/nifi/nifi-current/bin и установите логин и пароль командой ./nifi.sh set-single-user-credentials "admin" "admin1234567" где admin – логин, а admin1234567 – пароль (или любые другие реквизиты, пароль должен содержать 12 знаков или больше). О более сложных настройках аутентификации читайте в NiFi System Administrator’s Guide.
NiFi Expression Language
NiFi Expression Language – предметно-ориентированный язык (DSL), который можно использовать в большинстве конфигурационных параметров в процессорах Nifi, в основном для манипулирования атрибутами FlowFile-ов. Доступны булева логика, математические операции, операции со строками, датами и временем, функции поиска и некоторые другие.
Для устранения дублирования конфигурационных значений доступно создание и использование переменных. Обращение к их значению доступно через особый синтаксис NiFi Expression Language: ${VAR_NAME}. Переменные имеют область видимости (scope), заданные группой процессоров в которой эти переменные определяются. Если несколько переменных с одинаковым именем определены во вложенных друг в друга scope-ах, выбирается значение переменной из ближайшего scope, таким образом более специализированная версия переменной скрывает более общую.
Простота интеграции и текущее состояние
В Nifi есть способы интеграции с большинством популярных технологий, сервисов, форматов, протоколов и стеков. Все что вы видите в своем enterprise-проекте с большой долей вероятности можно как-то интегрировать с Nifi – если не через специально созданные компоненты (процессоры, контроллеры), то через стандартные абстракции (HTTP, AMQP, JDBC, etc.) и стандартизированные контроллеры / процессоры, которые их используют.
Nifi активно развивается, последний релиз на момент написания статьи: NiFi 2.0.0-M4 (выпущен в июле 2024) [^]. 25 ноября 2023 года вышла major версия 2 [^], описание основных новых фич можно прочесть в этой статье. NiFi версии 1.x могут работать с Java 8, NiFi версии 2.x требует Java 11.0.16 (минимум) [^].
Minifi
Minifi – дочерний проект для базовой ограниченной обработки потока данных на экстремально слабых системах (embedded systems, single-board computers, internet of things, smart-датчики и т.п.) с возможностью интеграции с Nifi.
Основная мотивация проекта – дать возможность обрабатывать потоки данных настолько близко к их источнику, насколько это возможно. Это может быть особенно удобным в ситуациях, когда обработка более выгодна средствами системы-источника локально, а не центральным сервером (например из-за низкой пропускной способности сети, большого количества систем источников с разными потребностями к обработке, ограничений правового регулирования и т.п.). Примеры:
- Источник создает большой поток событий, но вас интересует лишь малый процент из них (например, только события с ошибками), Minifi можно использовать для фильтрации, посылая по сети только то, что вам интересно.
- У вас множество источников данных, разбросанных по большой территории, поэтому вам требуется роутинг сообщений таким образом, чтобы данные из одного региона собирались в ближайшем дата-центре, также находящемся в этом регионе. Тогда на каждый источник можно установить Minifi и прописать конфигурацию по отправке данных в конкретный дата-центр в зависимости от местонахождения источника.
- В сообщениях источника содержится чувствительная информация (например, персональные данные), и законодательство обязывает вас принимать дополнительные меры по ее защите. Minifi может вырезать или зашифровать такую информацию прежде чем передавать данные дальше.
Также, экземпляры Minifi можно использовать в качестве легковесных агентов для простой обработки или роутинга данных на обычных серверах или в кластерной среде.
Minifi поставляется в двух имплементациях, как Linux native binary (С++) агент или как Java-агент. Прежде чем сделать выбор между этими двумя вариантами, принимайте во внимание, что имплементация на Java может содержать больше функций по сравнению с имплементацией на С++, т.к. для последнего приходится вести разработку с нуля, в то время как Java имплементация может переиспользовать код Nifi.
Сам Minifi не содержит UI, вся конфигурация прописывается в YAML, но при этом конфигурацией можно управлять централизованно через Command&Control сервер через API [^] [^], что дает возможность создавать клиентские UI для этих целей (например, Cloudera предоставляет Edge Flow Manager [^]).
Краткий обзор Minifi можно посмотреть в этом видео.
В третьей части расскажу, где NiFi оправдывает себя, а где нет, и объясню, почему бизнес-логику лучше держать вне NiFi.






{kind=link}