Наш хэд бэкэнд-разработки Женя — тот девелопер, который не просто играет с ИИ, а проверяет их на прочность и думает будет ли от них польза в реальных рабочих процессах. Используя LLM, он давно заметил очевидное: память модели заканчивается датой последнего обучения, а все новое остается за кадром. Retrieval Augmented Generation (RAG) решает эту проблему: вытаскивает свежие документы из баз или интернета, подмешивает их прямо в промпт и избавляет от затратного fine‑tuning модели. В статье Женя делится своими находками — как настроить RAG, ускорить ответы и сэкономить бюджет.
Все примеры кода и базовая схема реализации взяты с Baeldung
Что такое Retrieval Augmented Generation
Retrieval Augmented Generation — это архитектурный прием, который «пришивает» к языковой модели слой поиска и превращает ее ответы в динамический процесс.
Как работает цепочка?
- Извлечение. По запросу система ищет релевантные фрагменты в базах, корпоративных хранилищах или в сети.
- Обогащение промпта. Найденные куски текста вставляются в одно сообщение с вопросом.
- Генерация. LLM формулирует ответ, опираясь на свежий контекст, а не только на свои встроенные представления.
Таким образом, RAG не заменяет модель и не требует переобучения. Он просто соединяет поисковый механизм с генерацией так, чтобы каждый ответ строился на актуальных, проверенных данных.
Преимущества RAG-подхода
- Актуальность данных. Модель видит свежие документы сразу после их загрузки. Переобучать LLM не нужно.
- Фокус на сути. Документы режем на чанки. В prompt попадают только релевантные куски. Меньше шума — выше точность ответа.
- Экономия токенов и бюджета. Чанки короче исходных файлов, значит запрос дешевле. Плюс мы избегаем дорогого дообучения модели.
Где можно применить RAG
Начинаем работу: как устроен RAG‑конвейер
Это пример классической реализации пайплайна на базе RAG.
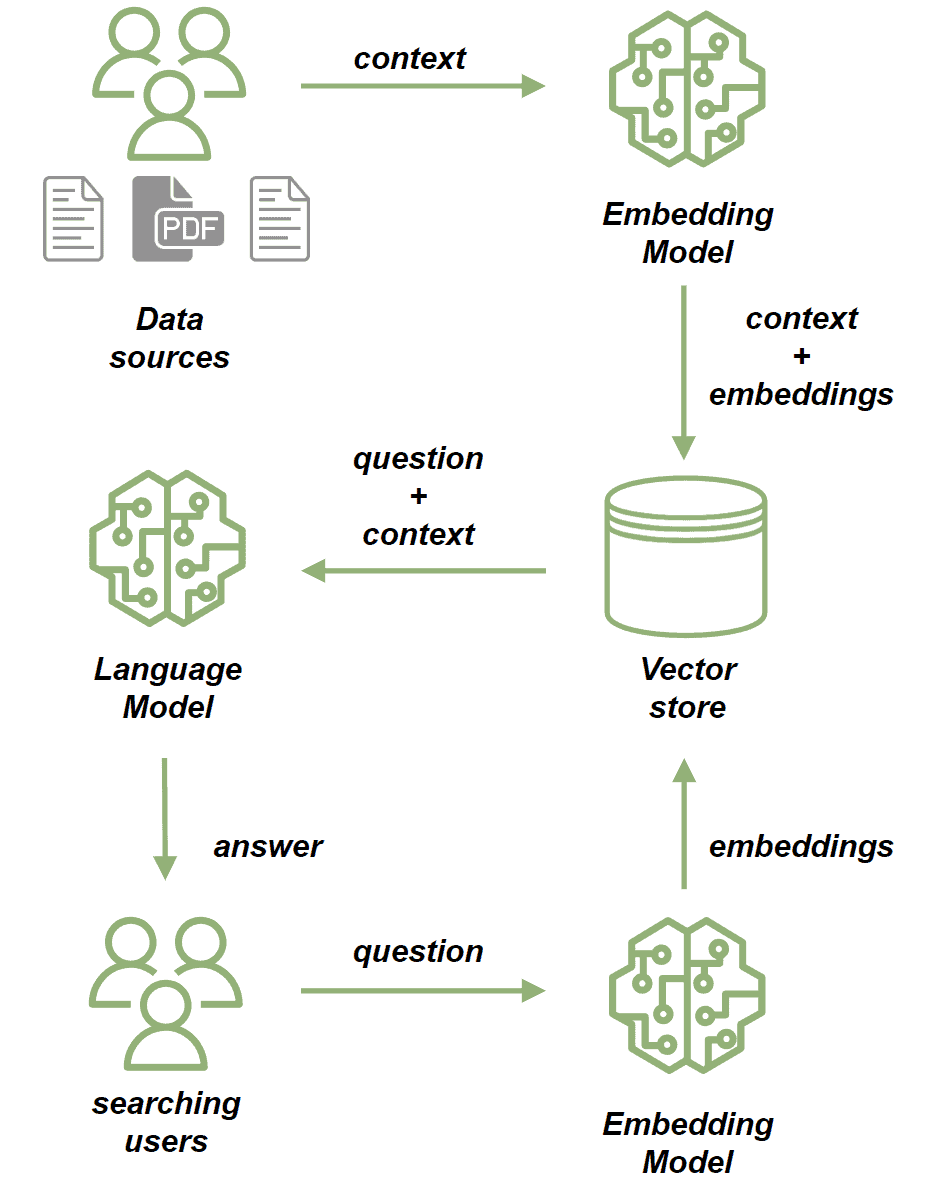
1. Индексация знаний
- Собираем источники: документы, PDF, базы.
- Режем на чанки — удобные по размеру куски текста.
- Строим эмбеддинги: прогоняем каждый чанк через модель embedding → получаем N‑мерный вектор (512, 1024 — зависит от модели).
- Сохраняем: кладем вектор и исходный текст в vector store.
2. Обслуживание запроса
- Пользователь задает вопрос.
- Генерируем эмбеддинг запроса той же моделью.
- Ищем ближайшие векторы в vector store → получаем релевантные чанки.
- Склеиваем prompt: вопрос + найденный контекст.
- LLM формирует ответ и отдает его пользователю.
Такой двухшаговый поток разделяет задачи. Индексация выполняется офлайн, сколько угодно долго. Retrieval и генерация работают онлайн за миллисекунды.
Этот паттерн остается одинаковым, даже если меняется способ поиска (векторный, keyword + вектор) или хранилище (Milvus, pgvector, Elastic).
Качественный retrieval всему голова
Ключевой компонент в RAG — поиск релевантных фрагментов. Без хорошего retrieval генерации просто будет не на что опираться.
Оба метода можно смешивать: сначала точный фильтр — отсекаем очевидный мусор, потом семантика — добавляем близкие по смыслу документы. Главное передать модели короткий, чистый контекст, пригодный для ответа.
Разметка текста — как нарезать чанки
Качественный retrieval начинается с правильного деления исходного материала. Вот какие способы существуют.
Коротко
- Для статичных, важных документов лучше ручная семантика.
- Для потоковых загрузок — автоматическая разметка: сначала грубый срез по токенам + overlap, со временем добавляем ML‑сегментацию.
- Размер чанка подбираем под модель и бюджет: чем меньше токенов — тем дешевле запрос, но выше риск потери контекста.
Сложности при внедрении RAG
- Динамическая разметка. Автоматические алгоритмы часто рвут смысл. Минимальный рабочий вариант — грубый сплит по токенам с overlap; затем подключаем ML‑сегментацию для тонкой правки свежего контента.
- Длина чанков. Короткие теряют контекст, длинные несут шум и удорожают запрос. Стартуем с 200‑500 токенов и overlap 10‑20 %, проверяем на реальных запросах и подгоняем порог опытным путем.
- Релевантность выдачи. KNN‑поиск может пропустить важный фрагмент или вернуть мусор.
- Накладные расходы. Векторная БД ест память и добавляет задержку. Храним горячие векторы в RAM, холодные — на SSD, используем HNSW‑индексы и кеширование, чтобы цепочка «поиск + LLM» укладывалась в SLA.
Как обработать PDF?Что делать с изображениями?
- Извлекаем текст (PDF‑miner, Tesseract для сканов).
- Чистим, режем на чанки, строим эмбеддинги.
- Кладем в vector store вместе с метаданными (имя файла, страница).
- Прогоняем картинку через CLIP или похожую модель → получаем визуальный эмбеддинг.
- (Опционально) генерируем текст‑описание через Vision‑LLM, чтобы LLM мог использовать контент как подсказку.
- Сохраняем эмбеддинг + текстовое описание в базе.
Векторные БД — что важно знать
Выбор движка
Открытого кода хватает: Faiss, Milvus, Weaviate, Chroma, Pinecone. Есть и модули для привычных хранилищ — Redis, Postgres, MongoDB. Все поддерживают базовый функционал KNN‑поиска, отличаются скоростью, объемом памяти, удобством администрирования.
Структура записи
- embedding — N‑мерный вектор.
- content — исходный текст (или ссылка на него).
- metadata — любые атрибуты: id, тип документа, язык. По ним удобно фильтровать результаты до ранжирования.
Запросы
- similarity threshold — порог близости (0‑1). Фильтрует шум.
- top k — сколько ближайших векторов вернуть. Чем выше k, тем больше шанс покрыть все релевантные чанки.
Индексация
Граф HNSW — дефолт для миллиона‑плюс векторов. IVF + PQ или DiskANN — если важна экономия памяти. Индекс подбирают экспериментально: измеряют latency и recall на боевых запросах.
Коротко
- Храним «горячие» индексы в RAM, «холодные» — на SSD.
- Держим отдельное поле для даты — позволяет резать выдачу по свежести.
- Стартовые значения: threshold 0.3‑0.4, k = 5‑10. Дальше тюним под метрики Precision и Recall.
Индексация документов в Spring AI
Это пример кода, реализации на базе Spring AI.

- Метаданные. Из исходного объекта берем нужные поля и кладем в Map.
- Документ. Создаем обертку, в которой текст и метаданные идут вместе.
- Чанки. TokenTextSplitter режет текст на блоки равной длины. Overlap отсутствует, поэтому часть контекста может пропасть. При желании пишем свой сплиттер.
- VectorStore. Метод add сам вызывает embedding‑модель, формирует векторы и сохраняет их вместе с текстом.
В итоге, пять строк кода и документ попадает в векторную БД. Spring AI берет на себя работу с эмбеддингами и хранением, остается лишь выбрать подходящий VectorStore и, при необходимости, доработать логику разбиения.
Поиск документов

VectorStore скрывает всю тяжелую работу. Мы передаем ему текст запроса, а он сам превращает строку в эмбеддинг, ищет ближайшие векторы в базе, возвращает найденные чанки.
Ключевые параметры:
- query — сам запрос.
- similarityThreshold — минимальная схожесть. Помогает отсеять шум.
- topK — сколько результатов нужно.
Возврат приходит уже списком Document. Достаем метаданные и контент — получаем строгий WikiDocument для дальнейшей обработки.
Минимум кода, никакой ручной работы с эмбеддинг‑моделью и индексом — Spring AI берет это на себя.
QuestionAnswerAdvisor: как связать поиск и LLM одной строкой
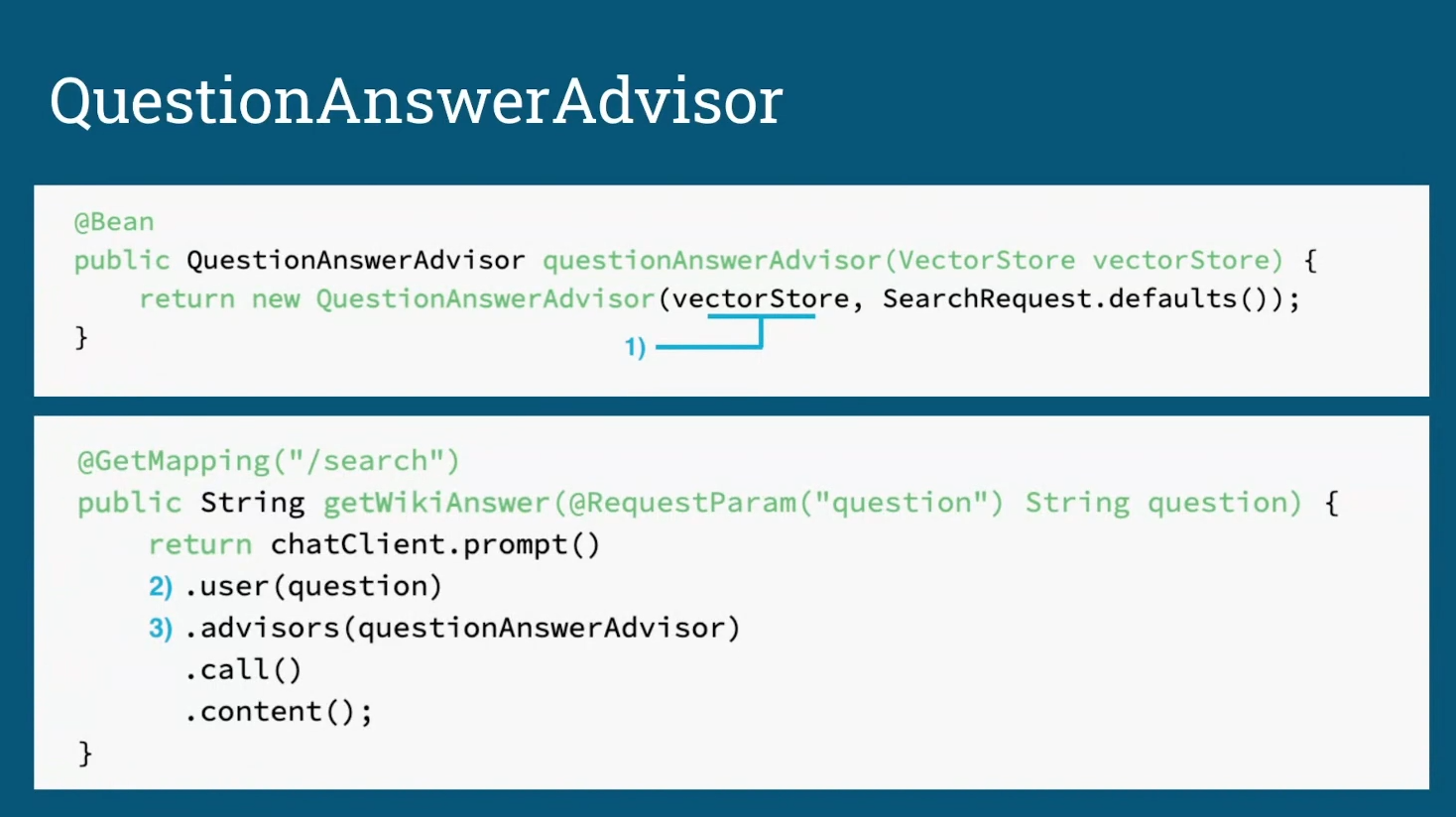
QuestionAnswerAdvisor — обертка, которая берет на себя весь RAG‑конвейер. В конструктор передаем:
- VectorStore — доступ к векторной БД.
- SearchRequest.defaults() — дефолтные параметры (threshold, top‑k). При желании подставляем свои.
Дальше в контроллере общаемся только с LLM‑клиентом:
@GetMapping("/search")
public String getWikiAnswer(@RequestParam("question") String question) {
return chatClient.prompt() // создаем prompt‑цепочку
.user(question) // текст запроса
.advisors(questionAnswerAdvisor) // подключаем RAG‑адвайзер
.call() // вызываем модель
.content(); // забираем ответ
}Что происходит под капотом:
- LLM‑клиент передает вопрос адвайзеру.
- Advisor делает embedding запроса, ищет релевантные чанки в VectorStore, формирует новый prompt (вопрос + контекст).
- Модель получает уже обогащенный prompt и генерирует ответ.
В итоге два бина и несколько строк в контроллере закрывают полный цикл «вопрос → поиск → генерация» без ручных вызовов embedding‑модели или индекса.
RAG и fine‑tuning: когда что выгоднее
Актуальность данных
RAG всегда читает свежие документы: добавили файл — индексация, и он уже в ответах. Fine‑tuning фиксирует знания на момент обучения, каждое обновление базы требует нового цикла дообучения.
Стоимость и время
RAG не переобучает модель, значит экономит GPU‑часы и деньги. Fine‑tuning — это платное обучение плюс пауза на эксперименты и валидацию.
КороткоКомбинация тоже возможна: дообученная модель + RAG для свежести.
- Берем RAG, если нужно работать с динамичными или закрытыми данными и быстро выводить их в прод.
- Выбираем fine‑tuning, когда важно изменить «стиль мышления» модели: научить ее отвечать по фирменному шаблону, писать код в своем стиле или корректно обрабатывать доменную терминологию.
Итоги
Retrieval Augmented Generation дает языковым моделям доступ к актуальным данным без затратного переобучения. Индексация новых документов занимает минуты, поэтому информация в ответах всегда свежая. Экономический эффект очевиден: расходы на GPU‑часы и инженерное время ниже, чем при регулярном fine‑tuning, а данные можно обновлять в режиме near‑real‑time.
Гибкость архитектуры позволяет подключать любые источники — корпоративную базу знаний, CRM, веб‑поиск — ровно тогда, когда это нужно бизнесу. Основные риски связаны с качеством поиска и задержкой отклика. Их можно контролировать метриками Precision/Recall, периодическим аудитом релевантности и оптимизацией индексов: «горячие» векторы держим в RAM, холодные переносим на SSD.
Наибольшую отдачу RAG приносит в сервисах поддержки, поисковых интерфейсах с готовым ответом, аналитических панелях и автоматической генерации отчетов. При этом важно понимать, что RAG не заменяет fine‑tuning, но, когда важна актуальность и точность данных, RAG обеспечивает быстрый и масштабируемый результат.





