
Обработка массивов данных «по-старинке» vs. алгоритмы машинного обучения
Меня зовут Александр Фомин, я CEO в IT-компании CosySoft. Мы занимаемся заказной разработкой веб и мобильных проектов, тестированием, проектированием веб-сервисов. На 98% — это enterprise, но есть и внутренние проекты, на которых тестируем привлекательные для команды технологии.
Недавно с коллегами мы запустили ML-направление, и предложили аналитическому агентству Автостат в коллаборации поработать над совместным проектом. С нас — экспертиза, с Автостата — данные и реально ценная для бизнеса задача. Это наши давние партнеры, которые многие годы собирают и обрабатывают колоссальные массивы данных, и на основе них проводятся статистические исследования авторынка России.
Агентство получает данные из разных источников, один из которых предоставляет около 60 000 строк смешанной информации, и их Автостату необходимо анализировать ежедневно. Мы предложили свое новое техническое решение, которое должно было улучшить результат этой работы.
Надеюсь, что в получившемся, хоть и техническом тексте, получится донести до менеджмента проектов и собственников, что эксперименты вроде нашего — это не только интересные задачки для инженеров.
Переписывание legacy-кода на новые технологии — это реальный профит, который на дистанции приносит экономию ресурсов и существенно улучшает метрики производительности вашего проекта. Некоторые из них мы тоже покажем.
Информация, интересующая «Автостат» — характеристики транспортных средств. В составе этих данных часто бывают блоки текстовой информации, которые заполняются произвольным образом. Информацию эту «Автостат» принимает в виде строки, например:
МаркаМодель LAND ROVER discovery 4 Наименование (тип ТС) легковойВ год выпуска 2011 тип№ двигателя дизельный306DT 0602415 кузовкабина sallaaaf4CA600000 цвет темно-коричневый Мощность двигателял. с. 2448 (180) Рабочий объем двигателякуб. см 2993 Организация- изготовитель ТС (страна) Ленд Ровер (Соединенное Королевство) Серия№ТДТПО 10009194/131211/0038186 ПТС 63 УС № 976457 от 14.12.2011 года
Это текстовое описание, в котором присутствует описание автомобиля и некоторая другая служебная информация. Из этой строки нужно вынуть интересующие характеристики — такие, как марка, модель и год выпуска. Сложность в том, что характеристики могут быть указаны как угодно: по-русски, по-английски, в падеже, без падежа, в скобках, без них. То есть это совершенно неструктурированный текст, введенный человеком в поле description или «описание».
У «Автостата» есть «Справочник синонимов»: это накопленный годами массив из уникальных вариантов написания всех марок и моделей на разных языках, в падежах и прочих формах. Компания дважды разрабатывала алгоритм, который брал строку и сравнивал ее с данными из справочника, но лучший результат этих экспериментов — 4 часа на 10 000 записей. Машинную обработку проводили на собственных серверах.
Поиск решения
«Автостат» предоставил нам файл из 10 000 строк с различными описательными характеристиками автомобилей и «Справочник синонимов». В обоих файлах имелась разметка по марке и модели автомобиля, но из-за того, что она создавалась много лет вручную, в ней было много ошибок.
Для замера качества поиска мы разметили:
- 7376 строк содержащих модель
- 8588 строк содержащих марку
- строки, содержащие год, не были размечены для проверки
Перед нами стояла задача распознавания именованных сущностей (Named-entity recognition, NER) из NLP. Для решения выбрали подход, основанный на правилах (rule based).
Создание словаря с марками и моделями
В словаре из 600 000 строк, предоставленным «Автостатом», содержались данные:
- text_brandmodel — строка, содержащая марку и модель. Может быть с опечатками, в транслите, с пропущенными пробелами;
- Brand_AS — бренд в верном написании на английском;
- Model_AS — модель в верном написании на английском.
Из этих данных мы создали словарь список марок автомобилей, который содержит:
- название марки и ее различные вариации наименований (на английском, на русском — автоматический транслит);
- список моделей и их различные вариации наименований (на английском, на русском — автоматический транслит).
Предобработка данных
Для успешной токенизации строк необходимо было уменьшить проблему «забытых» пробелов. Входящий текст мог содержать по 2-3 соединенных слова из-за отсутствия разделителя между характеристиками машины. Например: «Модель: RIO Цвет: белыйВид двигателя».
Для решения этой проблемы составили словарь, который содержит:
- список всех марок и моделей на английском и на русском языке длинной более трех символов;
- список частых слов (марка, модель, двигатель).
Частые слова нашли путем создания словаря и выявления частых суффиксов и префиксов.
Поиск именованных сущностей
Ниже представлена схема поиска марки и модели:

Для поиска года выпуска разработали другую схему. Основная проблема заключалась в отсутствии пробелов между цифрами, например: «Mersedes 3202021 года выпуска». Мы создали правило поиска токена, содержащего подстроку, подходящую под регулярное выражение — четырехзначное число в диапазоне от 1950 до 2022.
В результате этой операции поймали много «лишнего»: например, комбинации года и номера двигателя или номера модели (как в примере выше).
Следующий шаг — обнаружение позитивного и негативного окружения вокруг токена. Например, слова «год», «произведен» являются положительным окружением, а слова «номер», «двигатель» — негативным. В некоторых строках положительного окружения могло и не быть, например «Mersedes 3202021». Для таких случаев токен может быть годом, только если он содержит подходящие цифры один раз в строке.
Технология для решения
Для решения этой задачи мы выбрали библиотеку SpaCy. Внутри нее документ обрабатывается в несколько этапов:

Для проведения экспериментов был настроен MLFlow, в нем логировались результаты. MLFlow был развернут в варианте scenario 4 (s3, postgreSQL). Также было поднято Rest API с использованием FastAPI.
Предобработка данных
С помощью кастомного токенайзера текст предварительно обработали и местами внесли важные пропущенные пробелы перед тем, как строка попадает в трубу обработки текста.
Далее, на этапе NER сгенерировали правила по словарю с марками и моделями для обнаружения сущностей (см. пункт «Создание словаря с марками и моделями»).
Для реализации эвристик, то есть исследовательских методов, описанных в схеме пункта «Поиск именованных сущностей», создали кастомный этап обработки — расширение пайплайна. Внутри него мы реализовали:
- удаление «неподходящих» годов;
- разбивание токена содержащего год на 2-3 токена, зависимо от места вхождения;
- удаление «неподходящих» моделей;
- поиск «подходящих» марок и моделей, используя меру схожести Джаро-Винклера (уровень допустимости регулируется внутри словаря марок, для каждого наименования отдельно);
- поиск «подходящих» моделей, следующих сразу за маркой.
Что получилось?
«Автостат» ежедневно получает массив информации, и раньше цикл обработки растягивался от нескольких часов до двух суток — такая тактика была нежизнеспособной. Сейчас массивы получается обрабатывать за несколько минут.
В проведенных нами экспериментах было обработано 9653 строки.
Среди них:
- в 8587 найден бренд;
- в 7542 найдена модель;
- в 7290 найден год.
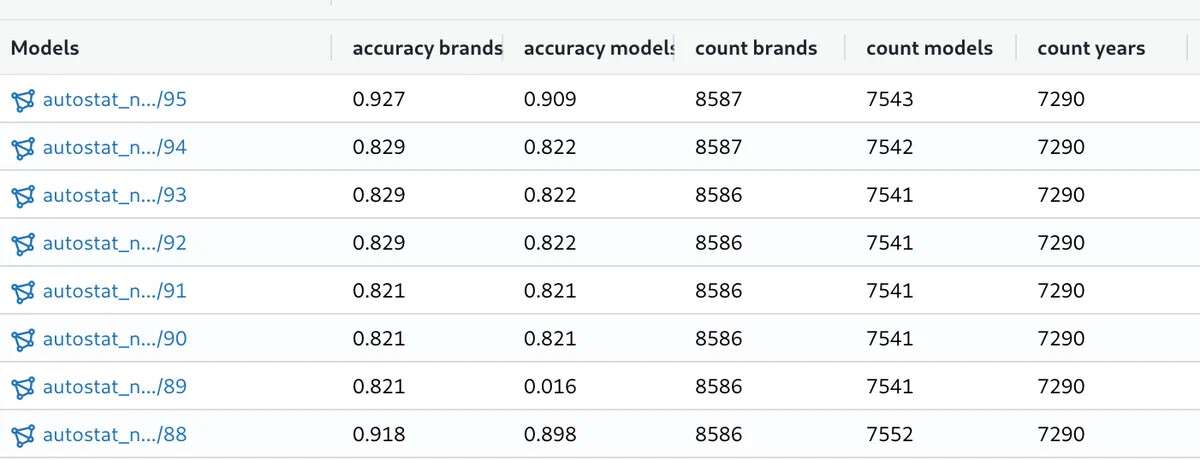
Благодаря корректировке методов обработки массивов повысилось и качество получаемой информации — точность найденной марки в нашей выборке составила 92,7%, а точность найденной модели 90,9%. Таких показателей не удавалось достичь с помощью исходного процесса обработки данных.
В итоге проекта — кратный рост скорости вычислений и качества обработанной информации. Что это значит для конечных клиентов Автостата? Удаление временного лага на получение обновленных данных и возросшая степень релевантности получаемых статистических исследований.
NDA нас ограничило в публичности финансовой стороны разработки и бизнесовых метрик, но вывод из них оказался следующим: если в вашем проекте приходится работать с большими объемами данных — эксперименты вроде описанного превосходят желаемый результат... И в 2022 году ML-решения для внедрений стали сильно доступнее, чем кажется 😉





