Наш бэкэнд-разработчик Оля наткнулась на перевод статьи Anthropica про паттерны для LLM-агентов с классными практическими примерами и решила получше разобраться, как это все работает.
Что такое агенты
Сначала разберемся, что такое агенты. Агенты — это системы, которые самостоятельно планируют действия и используют инструменты для решения задач. Каждый понимает агентов по-своему. Одни считают их полностью автономными решениями, способными долго работать без вмешательства. Другие видят в них более жесткие реализации, следующие заранее описанному процессу.
Отсюда появляются два типа: Workflows и собственно агенты.
- Workflows управляют набором инструментов через заранее прописанные участки кода и выполняют задачу по фиксированному сценарию.
- Агенты действуют гибко и сами контролируют свой процесс и инструменты.
Агенты возникают, когда у модели формируются возможности распознавать сложные вводы, планировать, пользоваться инструментами, восстанавливаться после ошибок и вести диалог. Чаще всего агент запускается вручную или реагирует на взаимодействие с человеком. Получив задачу, агент сам формирует план и действует. Периодически он может просить у человека уточнения или решение. При этом агенту важно получать актуальную информацию из окружающей среды: результаты вызовов инструментов или исполнения кода.
Завершается работа агента, когда задача выполнена или достигнут лимит итераций. Обычно код агента прост: одна или несколько моделей, которые циклически используют инструменты, опираясь на обратную связь. Но много времени уходит на подготовку инструментов, форматов данных, проектирование логики. Принцип «начинать с простого» и добавлять сложность по мере необходимости остается главным.
Фреймворки
Для создания агентных систем есть готовые фреймворки. LandGraph от LangChain, AI-агент из Amazon Bedrock, Rivet и Vellum предлагают удобные инструменты и графические интерфейсы. Эти решения помогают быстро вызвать модель, определить и обработать инструменты и объединить вызовы в цепочки. Но они создают дополнительные уровни абстракции, усложняя отладку.
Часто проще начать с прямого вызова API LLM. Многие паттерны можно зашить в короткий код, без громоздких фреймворков. Например, в Spring AI это выглядит лаконично. Если же фреймворк необходим, нужно разбираться в его внутренней механике. Это снизит риск распространенных ошибок и даст контроль над системой.
Model Context Protocol
Прежде чем переходить к паттернам разработки агентов, важно понять, что такое Model Context Protocol (MCP).
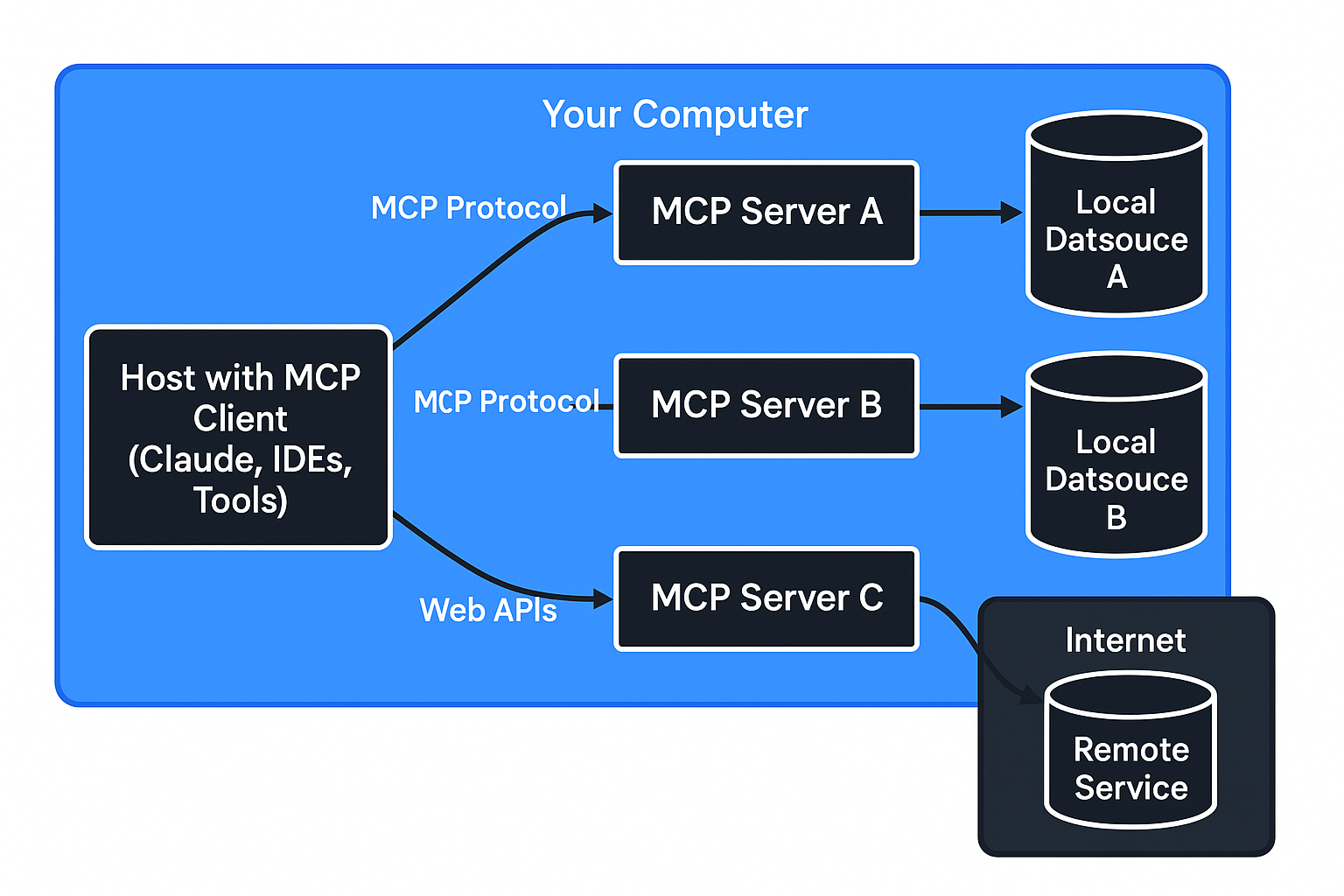
MCP — открытый протокол, который дает единый способ подключения моделей к локальным и удаленным ресурсам. Он построен по клиент-серверной архитектуре и делит систему на несколько частей:
• Host с клиентом — управляющая часть, которая отправляет запросы;
• Server — организует доступ к данным, инструментам, шаблонам;
• Local resource — локальные базы, файлы или процессы;
• Remote resource — внешние сервисы.
MCP имеет два уровня.
• Host с клиентом — управляющая часть, которая отправляет запросы;
• Server — организует доступ к данным, инструментам, шаблонам;
• Local resource — локальные базы, файлы или процессы;
• Remote resource — внешние сервисы.
MCP имеет два уровня.
- Protocol layer определяет формат сообщений и общую модель коммуникации.
- Transport layer отвечает за передачу данных и может использовать STDIO или HTTP (SSE или POST). Во всех случаях обмен идет по JSON-RPC 2.0. Протокол поддерживает несколько типов сообщений: запросы, результаты, ошибки и уведомления.
Как происходит подключение
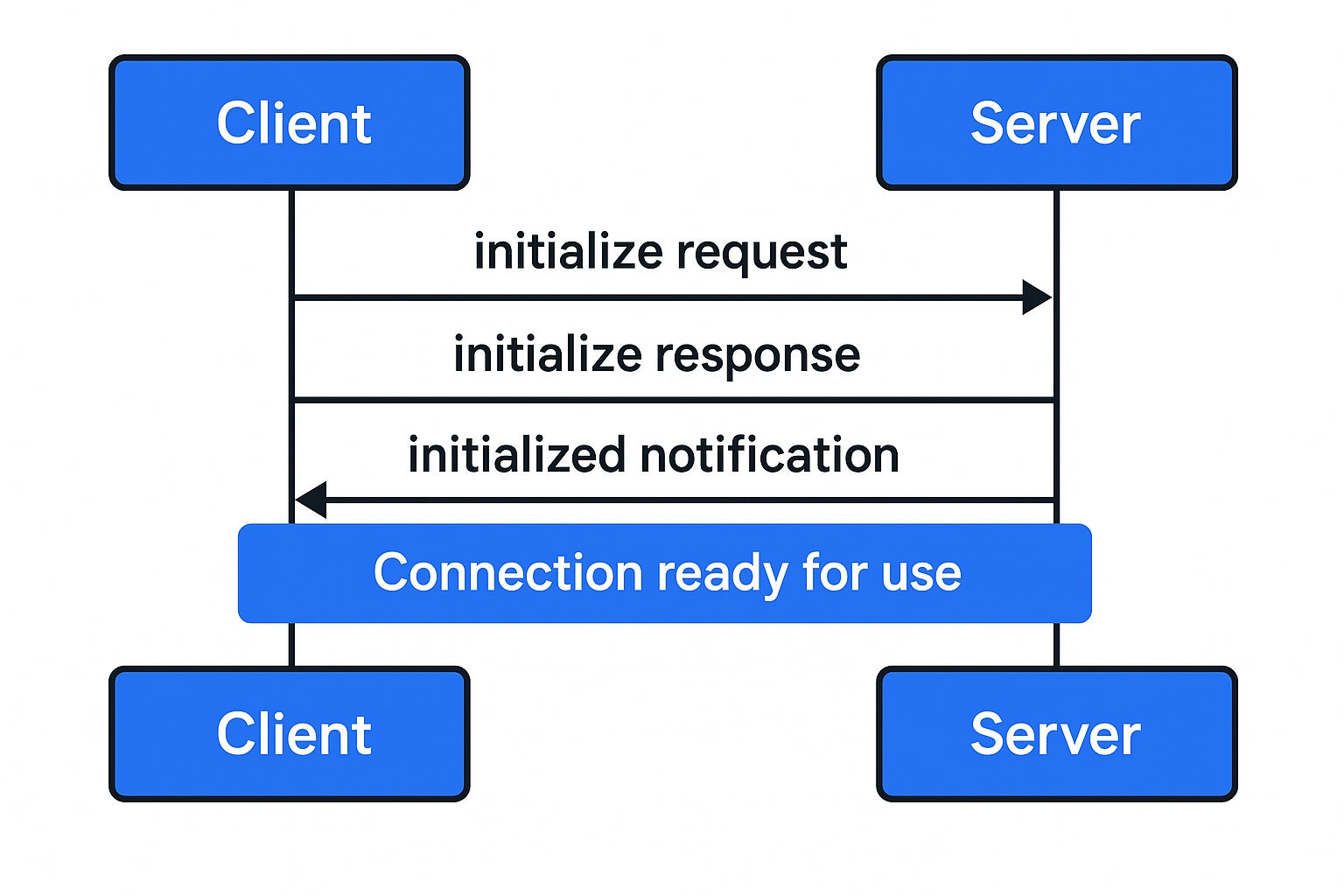
Подключение в MCP начинается с инициализации. Клиент отправляет запрос с версией протокола и своими возможностями. Сервер в ответ присылает свою версию и Capabilities. Клиент подтверждает получение. После этого стороны могут обмениваться сообщениями в формате вопрос-ответ или уведомления. Завершить соединение можно вызовом специального метода, транспортным разрывом или из-за ошибки.
Паттерны
Прежде чем углубляться в паттерны, уточню: под «моделью» во всех примерах имеется в виду «дополненная» LLM, которая не только генерирует ответы, но и может сама решать, какие инструменты использовать, какие поисковые запросы сформировать и какие данные нужно удерживать в памяти. Для этого Anthropic советуют:
- Адаптировать возможности модели под конкретный сценарий.
- Сделать интерфейс для модели простым и подробным.
Разные люди уже придумали кучу реализаций этих «дополнений». Но сейчас всем нравится Model Context Protocol (MCP), потому что он упрощает общение модели с нужными сервисами и ресурсами.
Workflow Prompt Chaining
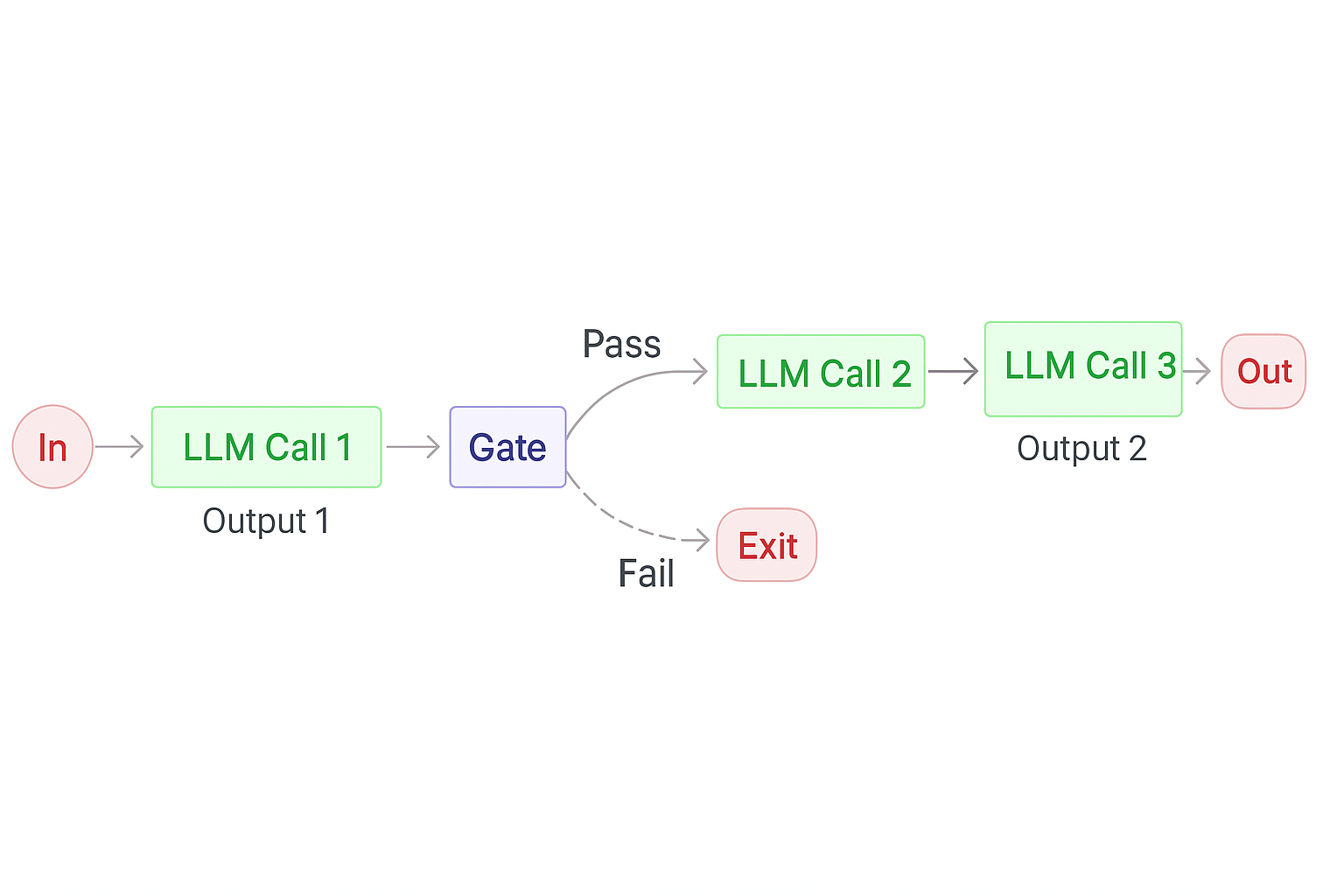
Первый паттерн — это Workflow Prompt Chaining, который разбивает задачу на ряд фиксированных подзадач. Каждый вызов модели обрабатывает результат предыдущего. Можно вставлять программные проверки, чтобы убедиться, что процесс идет правильно. Паттерн дает точный результат ценой дополнительных вызовов модели.
Для каких задач подойдет
Он удобен там, где задачу легко структурировать на несколько этапов. Пример — поэтапная подготовка и проверка черновика документа, а затем окончательное формирование текста.
Он удобен там, где задачу легко структурировать на несколько этапов. Пример — поэтапная подготовка и проверка черновика документа, а затем окончательное формирование текста.
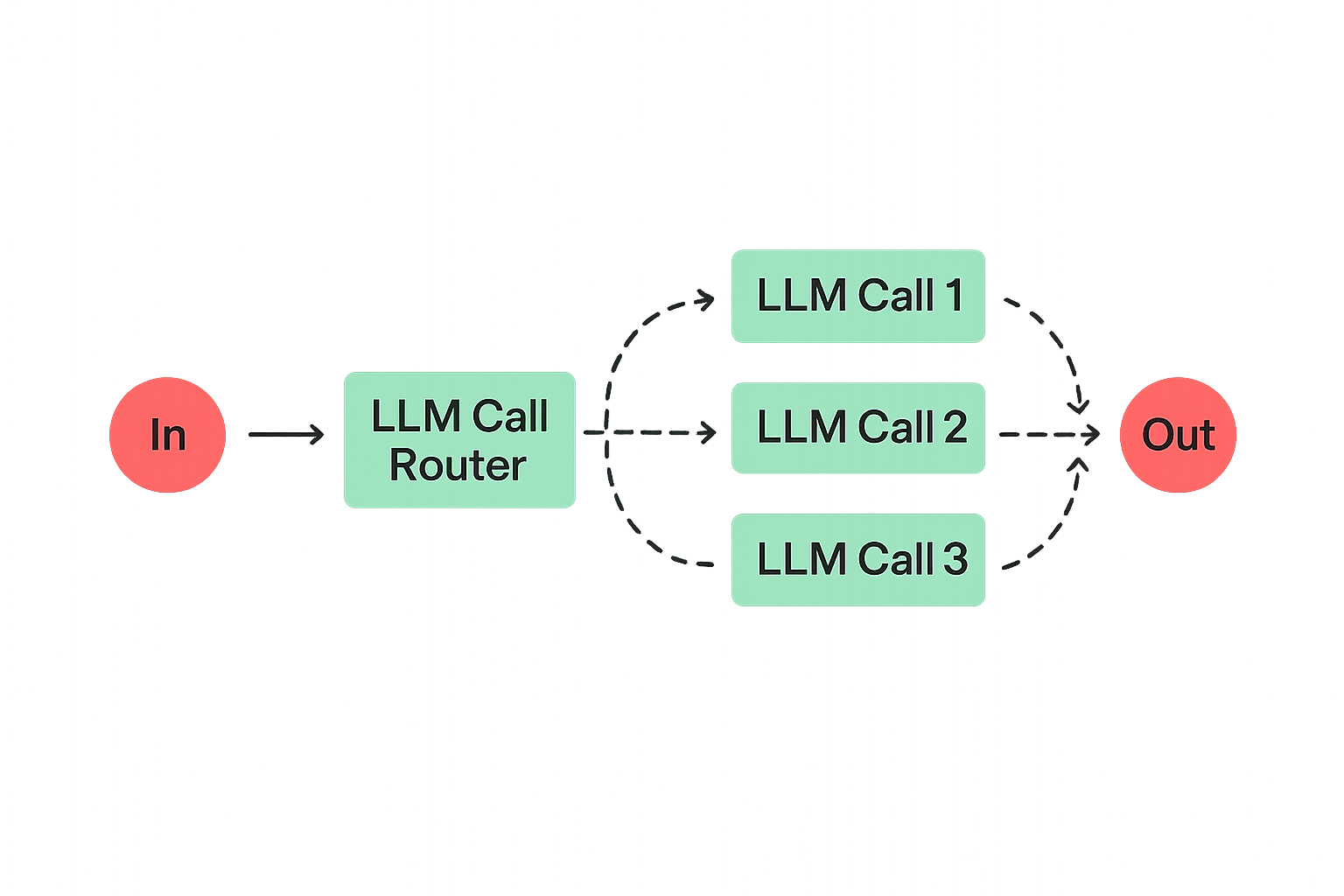
Routing
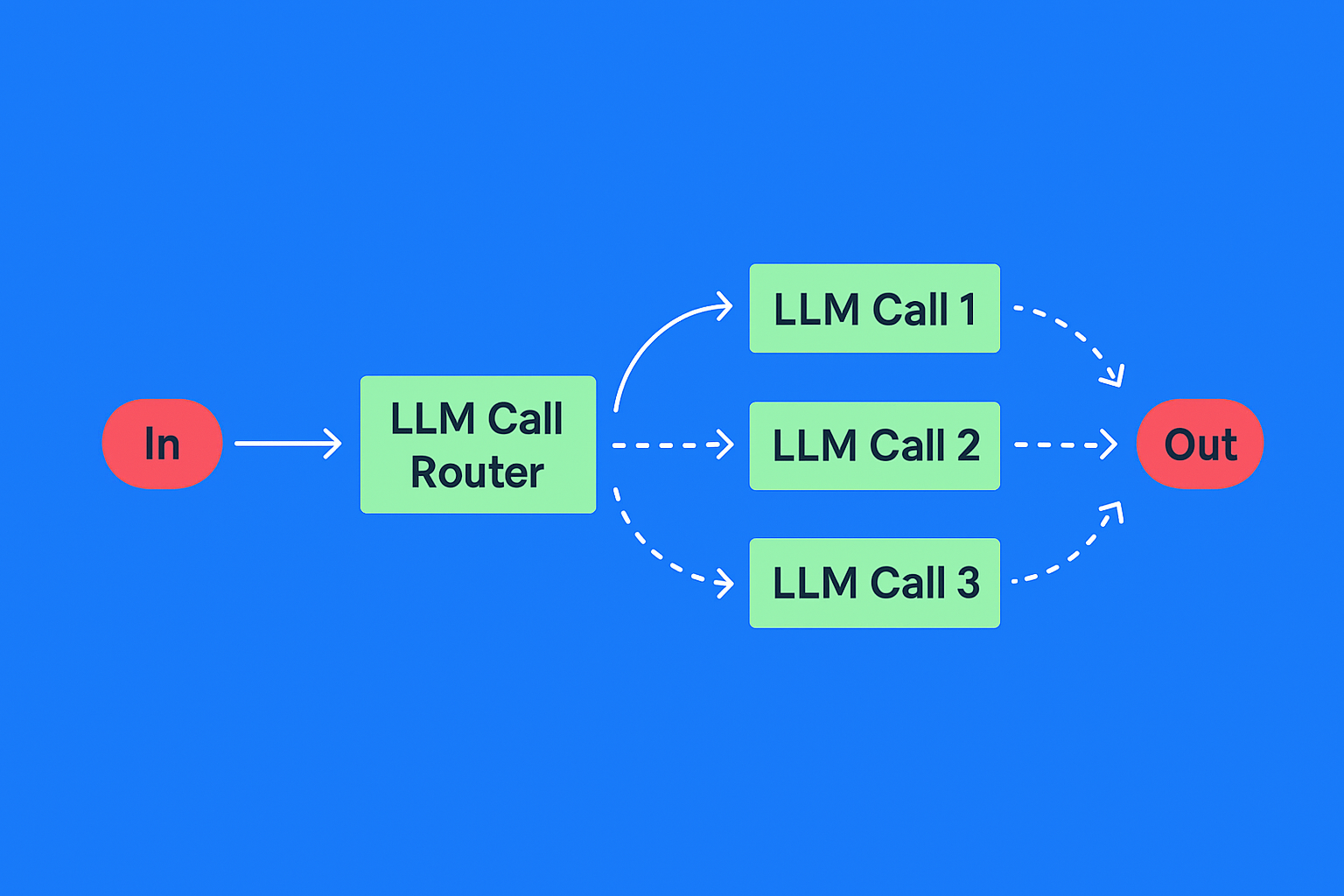
Паттерн Routing определяет тип входных данных и отправляет их на специализированную подсказку или модель. Он дает возможность гибко решать разные задачи и не жертвовать точностью ради универсальности.
Для каких задач подойдет
Подходит для систем, где есть четкие категории запросов с особыми требованиями: например, служба поддержки с разными типами обращений или проект, где простые запросы идут в дешевую модель, а сложные — в мощную.
Для каких задач подойдет
Подходит для систем, где есть четкие категории запросов с особыми требованиями: например, служба поддержки с разными типами обращений или проект, где простые запросы идут в дешевую модель, а сложные — в мощную.
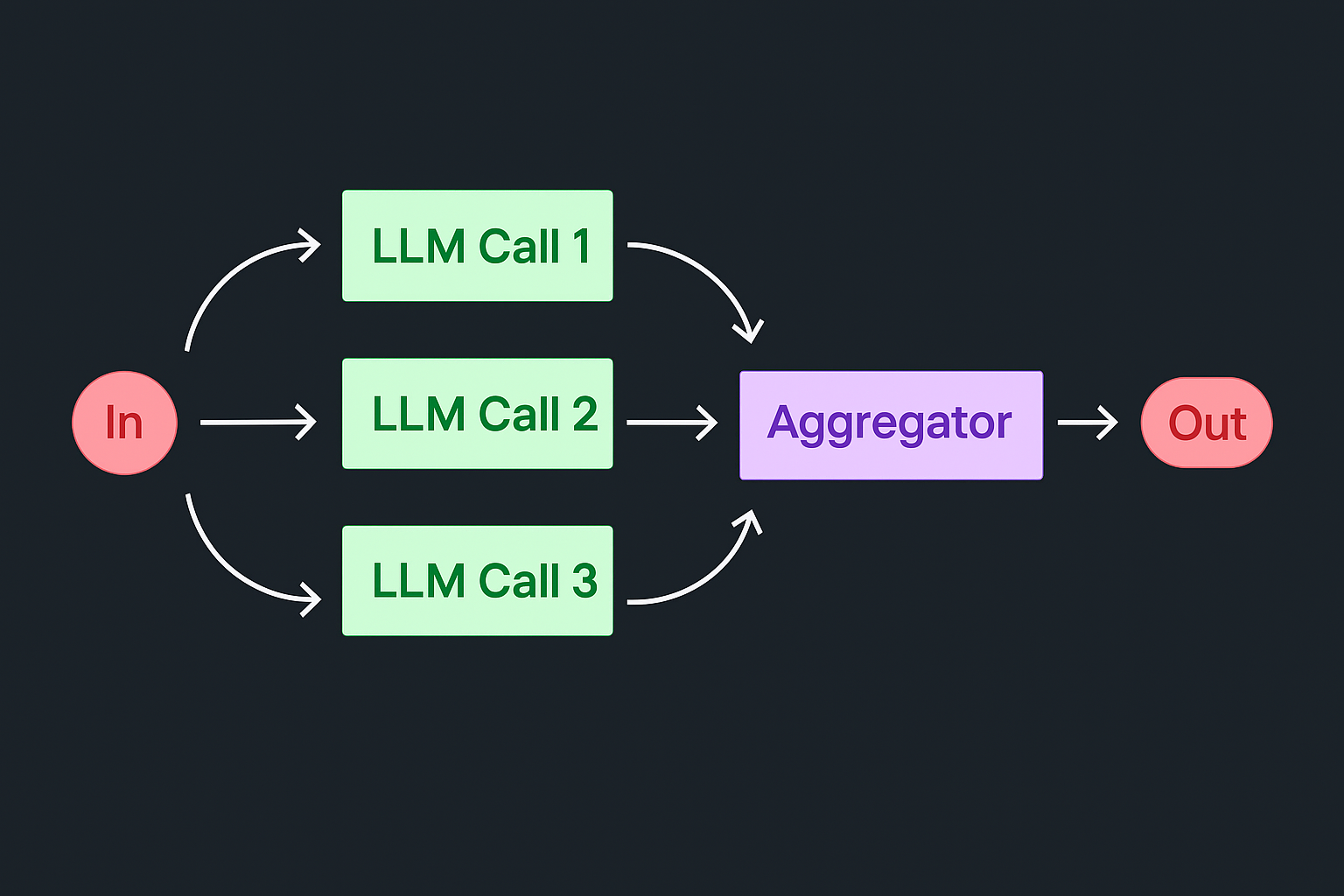
Parallelization
Паттерн Parallelization позволяет запускать модель на нескольких задачах одновременно и объединять результаты программно. Есть два ключевых сценария:
• Разбиение на секции: одна задача дробится на независимые подзадачи, каждая выполняется параллельно.
• Голосование: несколько экземпляров модели решают одну задачу, после чего система агрегирует результаты, выбирая итоговый вариант.
Для каких задач подойдет
Когда требуется быстрая обработка множества операций или повышенная точность за счет разных мнений модели.
Когда требуется быстрая обработка множества операций или повышенная точность за счет разных мнений модели.
Orchestrator-Workers
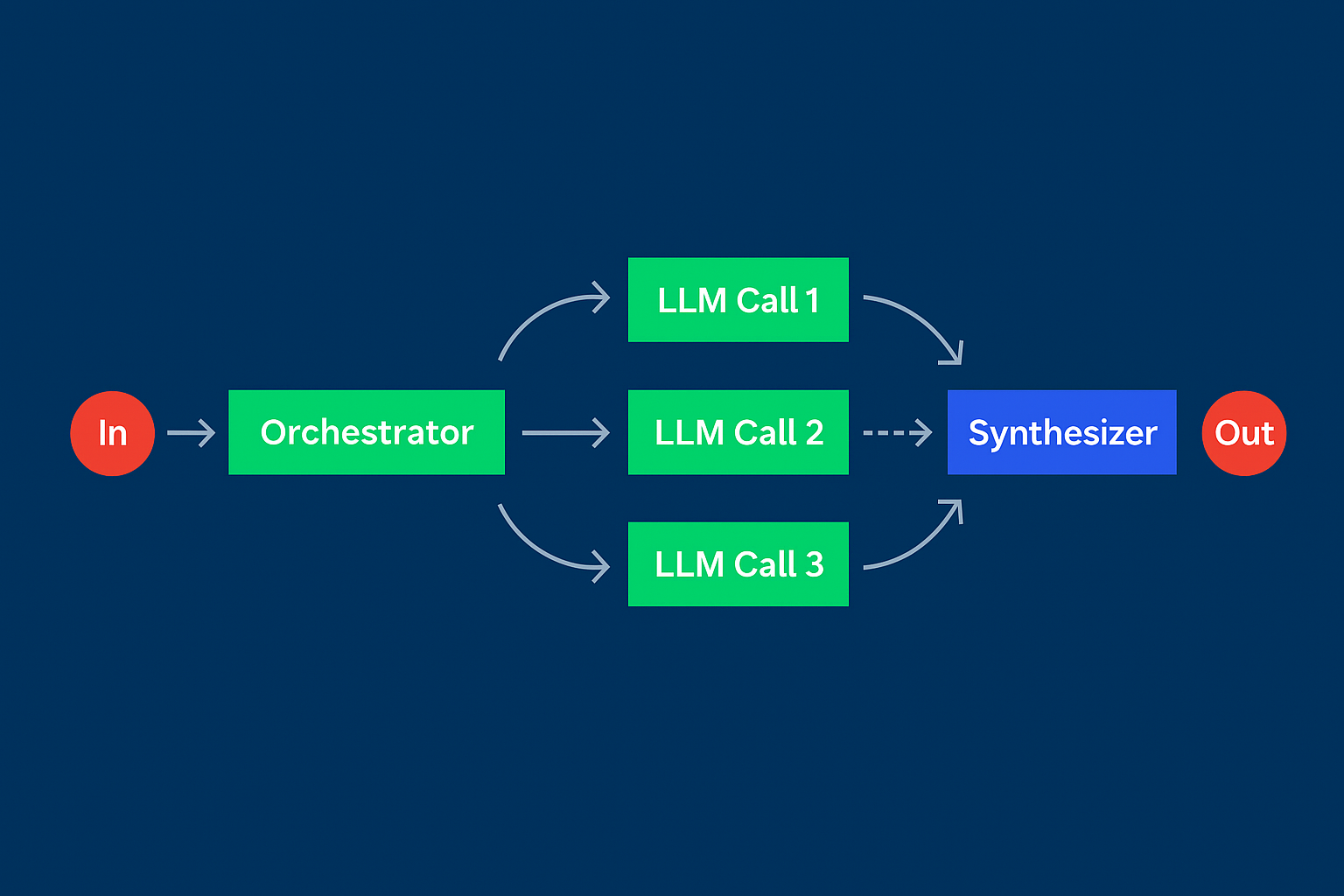
Паттерн Orchestrator-Workers помогает сохранять жесткий контроль над сложной задачей. Центральная модель (orchestrator) разбивает задачу на подзадачи, а специализированные компоненты (workers) их обрабатывают.
Для каких задач подойдет
Этот подход полезен, когда заранее неизвестно, какие подзадачи потребуются, или когда нужны разные методы решения. Например, при сборе и анализе данных из нескольких источников.
Для каких задач подойдет
Этот подход полезен, когда заранее неизвестно, какие подзадачи потребуются, или когда нужны разные методы решения. Например, при сборе и анализе данных из нескольких источников.
Evaluator-optimizer
Паттерн Evaluator-Optimizer (dual-LLM) использует две модели в итерационном цикле: одна генерирует ответы, другая оценивает и дает обратную связь. Процесс повторяется, пока итог не удовлетворяет оценку.
Для каких задач подойдет
Паттерн полезен, когда есть четкие критерии качества и выгода от нескольких итераций: перевод сложных текстов, многоэтапный поиск, где нужно несколько раундов анализа и экспертной проверки.
Для каких задач подойдет
Паттерн полезен, когда есть четкие критерии качества и выгода от нескольких итераций: перевод сложных текстов, многоэтапный поиск, где нужно несколько раундов анализа и экспертной проверки.
Запускаем первый проект
Попробовать паттерны проще всего на небольшом практическом проекте. Например, можно:
- Собрать простого «двойного агента»: одна LLM генерирует текст (или код), а вторая проверяет результат и дает обратную связь. Можно сделать несколько циклов улучшения. Такой эксперимент дает понимание, как настраивать форматы подсказок, как проверять корректность JSON и пр.
- Добавить RAG (Retrieval-Augmented Generation) в чат-бот для FAQ. Небольшая база текстов позволит модели выдавать релевантные ответы. По сути, тут весь основной объем хранится вне модели, а в запрос идет только нужный фрагмент.
- Попробовать Spring AI, где уже реализованы объекты вместо строк JSON. Это упрощает интеграцию, убирает рутинные моменты разбора результата.
Главное — начать с самых маленьких кейсов, чтобы увидеть, где потребуется дополнительная настройка. Уже на этапе «игрового» прототипа (вроде dual-LLM) обнаруживаются тонкости и понятно, сколько усилий уйдет на доработку.
Реальные примеры использования паттернов
- Оркестрация задач
- В простом чат-боте была «центральная» LLM, которая анализировала запрос пользователя и направляла его к отдельным агентам, каждый из которых имел доступ только к нужному набору инструментов (например, календарь, почта). Это позволило гибко подключать разные модели к разным задачам.
- Итеративное улучшение текста
- Программа для вычитки текста поэтапно редактировала материал: первая LLM генерировала правки, затем вторая оценивала результат. Процесс повторялся, пока не оставалось замечаний. Такой механизм автоматизировал часть редакторской работы.
- Система «экспертов»
- Для небольшой игровой логики были созданы несколько «экспертов»-LLM, каждый отвечал за свою часть правил (например, проверял соответствие описанного действия ресурсам или физическим ограничениям мира). Результаты каждого эксперта объединялись и формировали итоговое решение — реалистично ли действие игрока.
Финальные советы
Простые задачи часто превращаются в неожиданные проблемы, если модель игнорирует заданный формат. При настройке LLM нужно давать максимально точные инструкции и показывать примеры, охватывающие типовые случаи. Модели «меньшего калибра» требуют еще больше примеров, потому что у них меньше способностей к обобщению. Предварительная документация инструментов и форматов вывода экономит время и нервы. Чем тщательнее описаны кейсы, тем меньше неожиданностей при интеграции и тестировании. Лучше сначала реализовать упрощенную схему вызовов, довести ее до рабочей стадии и только потом повышать сложность.
Контекстное окно может стать узким местом, особенно при большом объеме данных. Многие современные модели предлагают внушительное контекстное окно (до десятков тысяч токенов), и в большинстве типовых сценариев этого хватает.
Если же объем все-таки превышает лимит, то можно применить такие подходы:
• RAG (Retrieval-Augmented Generation): хранить основной массив информации во внешнем хранилище, а модели передавать только релевантный фрагмент, найденный по векторному поиску.
• Дробление иерархии данных: разбивать ввод на части, вызывая модель поэтапно.
• Специализация агентов: каждый агент получает только свой набор инструментов и документации, что сокращает общий объем информации в одном вызове.





